PACs and Small Dollar Donations: Data Analysis
Environment Preperation
This section clears the current working environment and loads the packages used to visualize the data. I also create the function comma() to format any in-line output values to have thousands separators and only two digits.
# Clear Environment -----------------------------------------------------------
rm(list = ls())
# Load Packages ---------------------------------------------------------------
packages <- c("tidyverse", "foreign", "stargazer", "lme4", "multcomp",
"lmerTest", "ggmcmc", "ggridges", "rstan", "rstanarm", "brms",
"rethinking", "patchwork", "tidybayes", "sjstats", "sjPlot",
"bayesplot", "sjmisc", "ggpubr", "broom", "scales", "ggthemes",
"ggrepel", "BayesPostEst", "cmdstanr", "bayestestR")
lapply(packages, require, character.only = TRUE)
# Functions -------------------------------------------------------------------
# Inline Formatting
comma <- function(x) format(x, digits = 2, big.mark = ",")
# Inverse Hyperbolic Sin Transformation Function
ihs <- function(x) {
y <- log(x + sqrt(x^2 + 1))
return(y)
}
# Set Global Chunk Options ----------------------------------------------------
knitr::opts_chunk$set(
echo = TRUE,
warning = FALSE,
message = FALSE,
comment = "##",
R.options = list(width = 70)
)Import Data
This section imports the data cleaned in the “Step I: Data Cleaning” document to begin analyzing the data.
load("Data/Clean Data/estimation_data.Rda")
#load("E:/Project/Data/Clean Data/estimation_data.RDa")
estimation.data <-
estimation.data %>%
mutate(pct_white_c = std(pct_white, robust = "2sd"),
pct_black_c = std(pct_black, robust = "2sd"),
pct_latino_c = std(pct_latino, robust = "2sd"),
pct_asian_c = std(pct_asian, robust = "2sd"),
pct_bachelors_c = std(pct_bachelors, robust = "2sd"),
pct_clinton_16_c = std(pct_clinton_16, robust = "2sd"),
pct_dem_house_16_c = std(pct_dem_house_16, robust = "2sd"),
log_tot_voting_age_c = std(log_tot_voting_age, robust = "2sd"),
log_median_hh_income_c = std(log_median_hh_income, robust = "2sd"))
estimation.data <-
estimation.data %>%
mutate(chamber = str_sub(district, start = -2L, end = -1L),
chamber = ifelse(str_detect(chamber, pattern = "S"), "Senate", "House"),
vote_margin = vote_pct - 50) %>%
filter(chamber == "House") %>%
filter(vote_pct > 50)PAC Models
Model Fitting
biz.pac.fit <- brm(bf(business_pacs ~ no_corp_pacs + new_member + pct_white_c +
pct_black_c + pct_latino_c + pct_asian_c +
pct_bachelors_c + pct_clinton_16_c +
pct_dem_house_16_c + log_tot_voting_age_c +
log_median_hh_income_c,
hu ~ no_corp_pacs + new_member),
family = hurdle_gamma(link = "log", link_hu = "logit"),
prior = c(prior(normal(13, 12), class = Intercept),
prior(normal(-1, 0.5), class = b,
coef = "no_corp_pacsYES"),
prior(normal(0, 0.5), class = b),
prior(normal(0, 1), dpar = "hu", class = Intercept),
prior(normal(0, 0.5), dpar = "hu", class = b)),
sample_prior = "yes",
cores = 4,
iter = 4000,
backend = "cmdstan",
silent = 2,
refresh = 0,
data = estimation.data)## Running MCMC with 4 parallel chains...
##
## Chain 4 finished in 3.4 seconds.
## Chain 1 finished in 3.4 seconds.
## Chain 3 finished in 3.4 seconds.
## Chain 2 finished in 3.9 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 3.5 seconds.
## Total execution time: 4.0 seconds.describe_posterior(biz.pac.fit, ci = 0.9, ci_method = "hdi",
test = c("p_direction"))## Summary of Posterior Distribution
##
## Parameter | Median | 90% CI | pd | Rhat | ESS
## ----------------------------------------------------------------------------
## (Intercept) | 13.05 | [12.96, 13.15] | 100% | 1.000 | 11709.00
## hu_Intercept | -3.37 | [-3.97, -2.80] | 100% | 1.000 | 8827.00
## no_corp_pacsYES | -1.55 | [-1.82, -1.30] | 100% | 1.000 | 9144.00
## new_memberYES | -1.97 | [-2.21, -1.72] | 100% | 1.000 | 8029.00
## pct_white_c | 0.16 | [-0.36, 0.70] | 68.81% | 1.001 | 3633.00
## pct_black_c | -0.22 | [-0.60, 0.22] | 80.66% | 1.000 | 3516.00
## pct_latino_c | -0.01 | [-0.43, 0.42] | 52.55% | 1.000 | 3604.00
## pct_asian_c | -0.21 | [-0.50, 0.06] | 88.75% | 1.000 | 4708.00
## pct_bachelors_c | -0.15 | [-0.48, 0.15] | 78.03% | 1.000 | 5856.00
## pct_clinton_16_c | -0.02 | [-0.37, 0.32] | 54.34% | 1.000 | 5638.00
## pct_dem_house_16_c | 0.25 | [-0.02, 0.53] | 93.49% | 1.000 | 6966.00
## log_tot_voting_age_c | -0.05 | [-0.23, 0.14] | 68.65% | 1.000 | 10175.00
## log_median_hh_income_c | 0.04 | [-0.25, 0.32] | 58.64% | 1.000 | 6906.00
## hu_no_corp_pacsYES | 0.95 | [ 0.32, 1.60] | 99.22% | 1.000 | 9964.00
## hu_new_memberYES | 0.73 | [ 0.07, 1.38] | 96.73% | 1.000 | 9493.00
##
## # Fixed effects priors
##
## Parameter | Rhat | ESS
## ---------------------------
## shape | 1.000 | 8163.00
## shape | 1.000 | 8163.00num.pac.fit <- brm(num_pac_contribs ~ no_corp_pacs + new_member + pct_white_c +
pct_black_c + pct_latino_c + pct_asian_c +
pct_bachelors_c + pct_clinton_16_c +
pct_dem_house_16_c + log_tot_voting_age_c +
log_median_hh_income_c,
family = negbinomial(link = "log"),
prior = c(prior(normal(7, 6), class = Intercept),
prior(normal(-1, 0.5), class = b,
coef = "no_corp_pacsYES"),
prior(normal(0, 0.5), class = b)),
sample_prior = "yes",
cores = 4,
iter = 4000,
backend = "cmdstan",
silent = 2,
refresh = 0,
data = estimation.data)## Running MCMC with 4 parallel chains...
##
## Chain 2 finished in 1.1 seconds.
## Chain 1 finished in 1.1 seconds.
## Chain 3 finished in 1.1 seconds.
## Chain 4 finished in 1.2 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 1.1 seconds.
## Total execution time: 1.3 seconds.describe_posterior(num.pac.fit, ci = 0.9, ci_method = "hdi",
test = c("p_direction"))## Summary of Posterior Distribution
##
## Parameter | Median | 90% CI | pd | Rhat | ESS
## ---------------------------------------------------------------------------
## (Intercept) | 5.98 | [ 5.90, 6.05] | 100% | 1.000 | 9370.00
## no_corp_pacsYES | -0.65 | [-0.85, -0.46] | 100% | 1.000 | 7750.00
## new_memberYES | -1.08 | [-1.27, -0.88] | 100% | 1.000 | 7367.00
## pct_white_c | 0.13 | [-0.37, 0.62] | 66.46% | 1.000 | 4220.00
## pct_black_c | -0.04 | [-0.42, 0.34] | 57.55% | 1.000 | 4093.00
## pct_latino_c | 0.12 | [-0.28, 0.51] | 69.33% | 1.000 | 4280.00
## pct_asian_c | -0.23 | [-0.47, 0.02] | 93.35% | 1.000 | 5239.00
## pct_bachelors_c | -0.02 | [-0.27, 0.23] | 55.77% | 1.000 | 5815.00
## pct_clinton_16_c | -0.29 | [-0.58, -0.02] | 95.51% | 1.000 | 5644.00
## pct_dem_house_16_c | 0.06 | [-0.14, 0.27] | 68.79% | 1.000 | 6347.00
## log_tot_voting_age_c | -0.05 | [-0.18, 0.10] | 71.65% | 1.000 | 9052.00
## log_median_hh_income_c | 0.10 | [-0.13, 0.32] | 76.14% | 1.000 | 6627.00
##
## # Fixed effects priors
##
## Parameter | Rhat | ESS
## ---------------------------
## shape | 1.000 | 7494.00
## shape | 1.000 | 7494.00Model Diagnostics
Prior Influence
# business pac contributions
biz.pac.priors <- prior_samples(biz.pac.fit)
biz.pac.post <- posterior_samples(biz.pac.fit)
ggplot() +
geom_density(data = biz.pac.priors, aes(x = b_no_corp_pacsYES)) +
geom_density(data = biz.pac.post, aes(x = b_no_corp_pacsYES))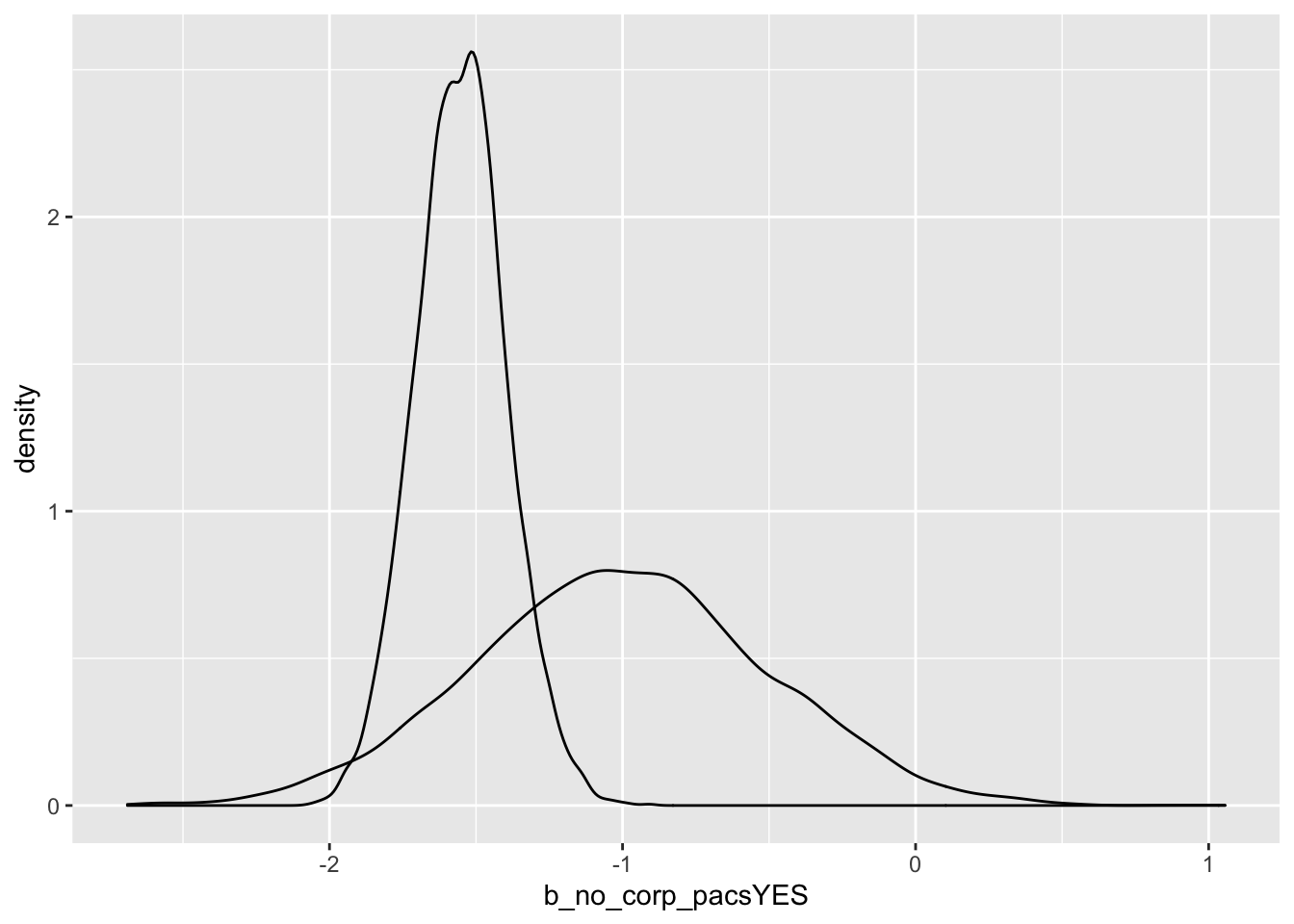
# number of business pac contributions
num.pac.priors <- prior_samples(num.pac.fit)
num.pac.post <- posterior_samples(num.pac.fit)
ggplot() +
geom_density(data = num.pac.priors, aes(x = b_no_corp_pacsYES)) +
geom_density(data = num.pac.post, aes(x = b_no_corp_pacsYES))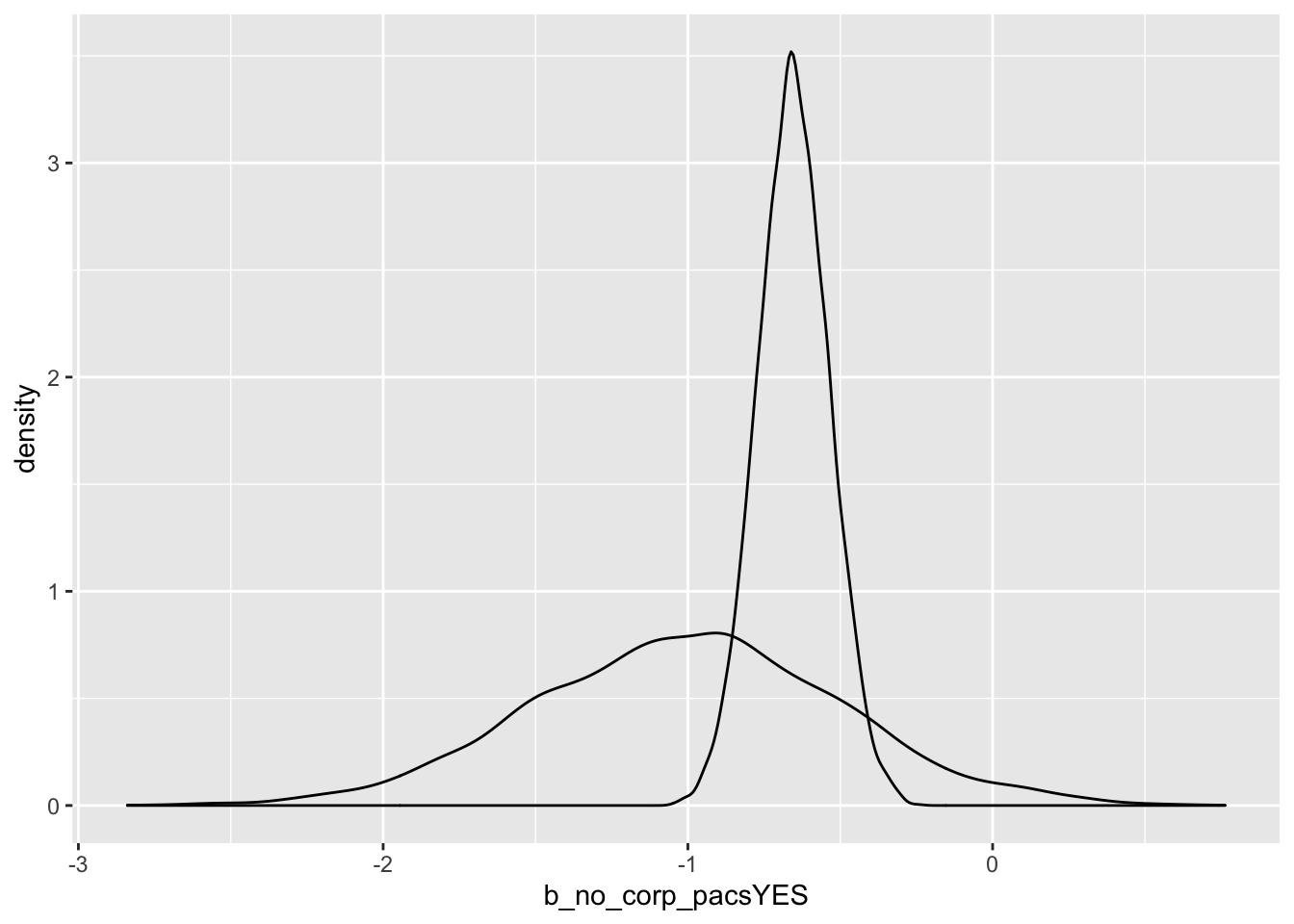
Posterior Predictive Checks
# business pac contributions --------------------------------------------------
y.biz.pac <-
estimation.data %>%
pull(business_pacs)
# extract the fitted values
y.rep <- posterior_predict(biz.pac.fit, draws = 500)
dim(y.rep)## [1] 8000 221ppc_dens_overlay(y = y.biz.pac[1:ncol(y.rep)], yrep = y.rep[1:100, ])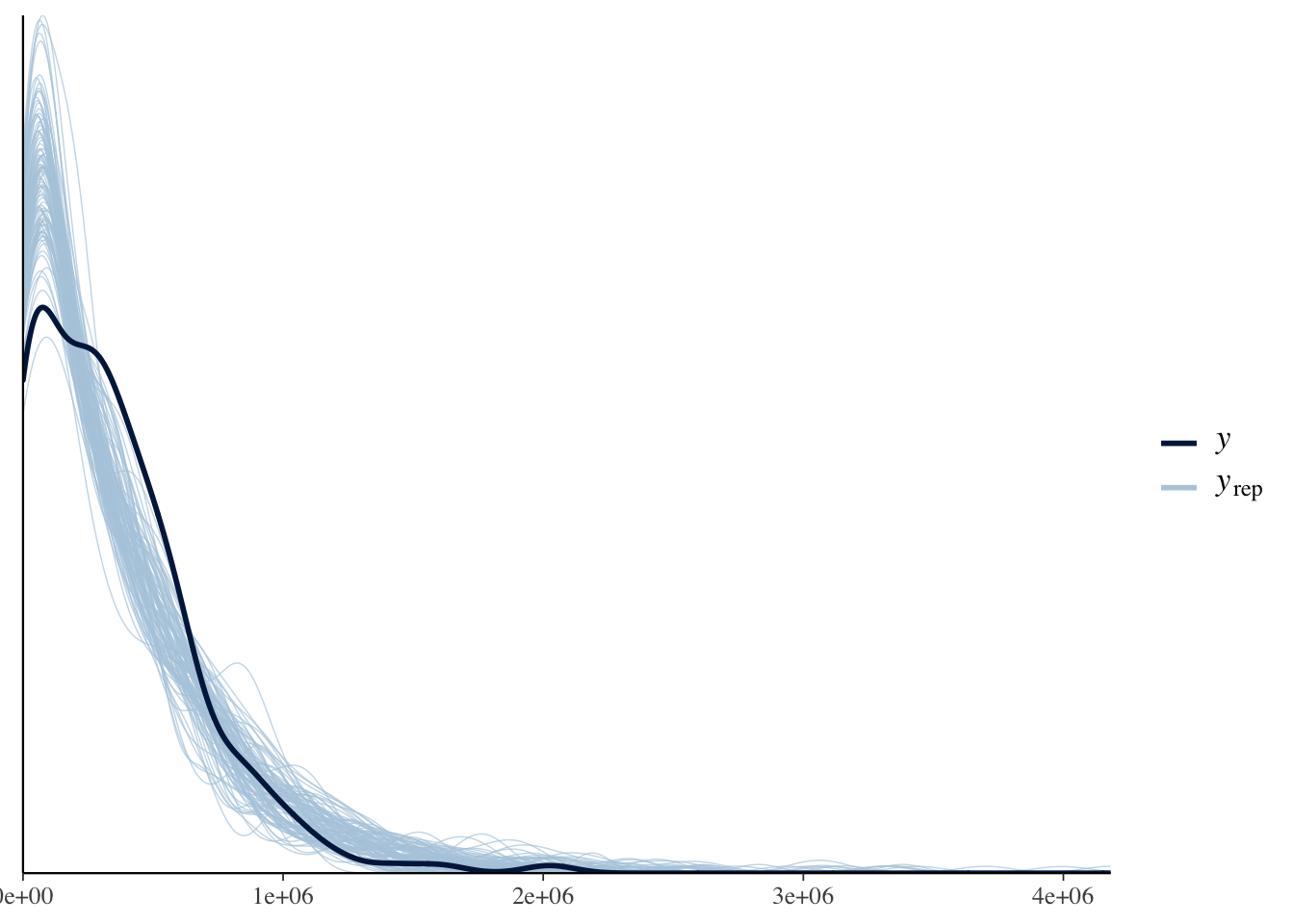
# number business pac contributors --------------------------------------------
y.num.pac <-
estimation.data %>%
pull(num_pac_contribs)
# extract the fitted values
y.rep <- posterior_predict(num.pac.fit, draws = 500)
dim(y.rep)## [1] 8000 221ppc_dens_overlay(y = y.num.pac[1:ncol(y.rep)], yrep = y.rep[1:100, ])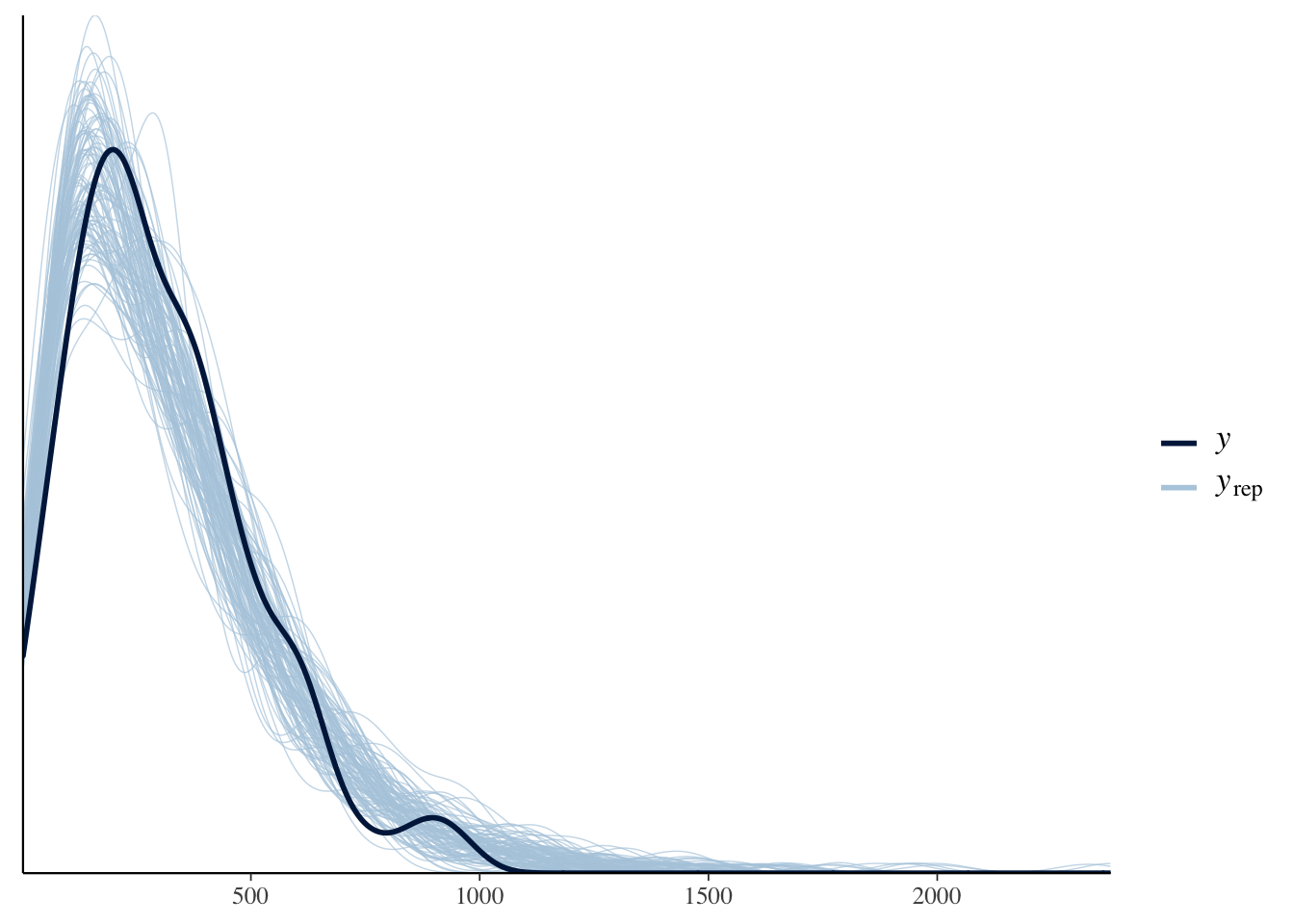
Model Results
Results Tables
library(xtable)
# Business PAC Fit
xtable(describe_posterior(biz.pac.fit, ci = 0.9, ci_method = "hdi",
test = c("p_direction")))## % latex table generated in R 4.2.0 by xtable 1.8-4 package
## % Wed Jul 13 10:38:16 2022
## \begin{table}[ht]
## \centering
## \begin{tabular}{rlrrrrrrr}
## \hline
## & Parameter & Median & CI & CI\_low & CI\_high & pd & Rhat & ESS \\
## \hline
## 4 & b\_Intercept & 13.05 & 0.90 & 12.96 & 13.15 & 1.00 & 1.00 & 11709.24 \\
## 1 & b\_hu\_Intercept & -3.37 & 0.90 & -3.97 & -2.80 & 1.00 & 1.00 & 8826.98 \\
## 8 & b\_no\_corp\_pacsYES & -1.55 & 0.90 & -1.82 & -1.30 & 1.00 & 1.00 & 9143.88 \\
## 7 & b\_new\_memberYES & -1.97 & 0.90 & -2.21 & -1.72 & 1.00 & 1.00 & 8029.17 \\
## 15 & b\_pct\_white\_c & 0.16 & 0.90 & -0.36 & 0.70 & 0.69 & 1.00 & 3633.44 \\
## 11 & b\_pct\_black\_c & -0.22 & 0.90 & -0.60 & 0.22 & 0.81 & 1.00 & 3515.65 \\
## 14 & b\_pct\_latino\_c & -0.01 & 0.90 & -0.43 & 0.42 & 0.53 & 1.00 & 3603.74 \\
## 9 & b\_pct\_asian\_c & -0.21 & 0.90 & -0.50 & 0.06 & 0.89 & 1.00 & 4708.01 \\
## 10 & b\_pct\_bachelors\_c & -0.15 & 0.90 & -0.48 & 0.15 & 0.78 & 1.00 & 5856.25 \\
## 12 & b\_pct\_clinton\_16\_c & -0.02 & 0.90 & -0.37 & 0.32 & 0.54 & 1.00 & 5638.33 \\
## 13 & b\_pct\_dem\_house\_16\_c & 0.25 & 0.90 & -0.02 & 0.53 & 0.93 & 1.00 & 6966.11 \\
## 6 & b\_log\_tot\_voting\_age\_c & -0.05 & 0.90 & -0.23 & 0.14 & 0.69 & 1.00 & 10175.48 \\
## 5 & b\_log\_median\_hh\_income\_c & 0.04 & 0.90 & -0.25 & 0.32 & 0.59 & 1.00 & 6905.71 \\
## 3 & b\_hu\_no\_corp\_pacsYES & 0.95 & 0.90 & 0.32 & 1.60 & 0.99 & 1.00 & 9963.86 \\
## 2 & b\_hu\_new\_memberYES & 0.73 & 0.90 & 0.07 & 1.38 & 0.97 & 1.00 & 9492.82 \\
## 16 & prior\_shape & & & & & & 1.00 & 8163.01 \\
## \hline
## \end{tabular}
## \end{table}Coefficient Plots
# Gamma Likelihood ------------------------------------------------------------
# extract posterior predictions
biz.pac.coef <-
biz.pac.fit %>%
spread_draws(b_no_corp_pacsYES) %>%
mutate(model = "Business PAC $")
## main effects
library(latex2exp)
biz.pac.coef %>%
mutate(b_np = exp(b_no_corp_pacsYES) - 1) %>%
ggplot() +
stat_halfeyeh(aes(y = fct_reorder(model, b_np), x = b_np),
.width = c(0.9),
point_interval = median_hdi,
fill = "#A4A4A4",
color = "black",
alpha = 0.9) +
geom_vline(aes(xintercept = 0), linetype = "dashed", color = "grey55") +
scale_x_continuous(labels = percent_format(),
breaks = pretty_breaks(n = 6)) +
labs(x = TeX("% Change in Contributions ($\\e^{\\beta} - 1$)"),
y = "Outcome Variable") +
theme_pubr() +
theme(axis.text.y = element_text(angle = 90, vjust = 0, hjust = 0.5))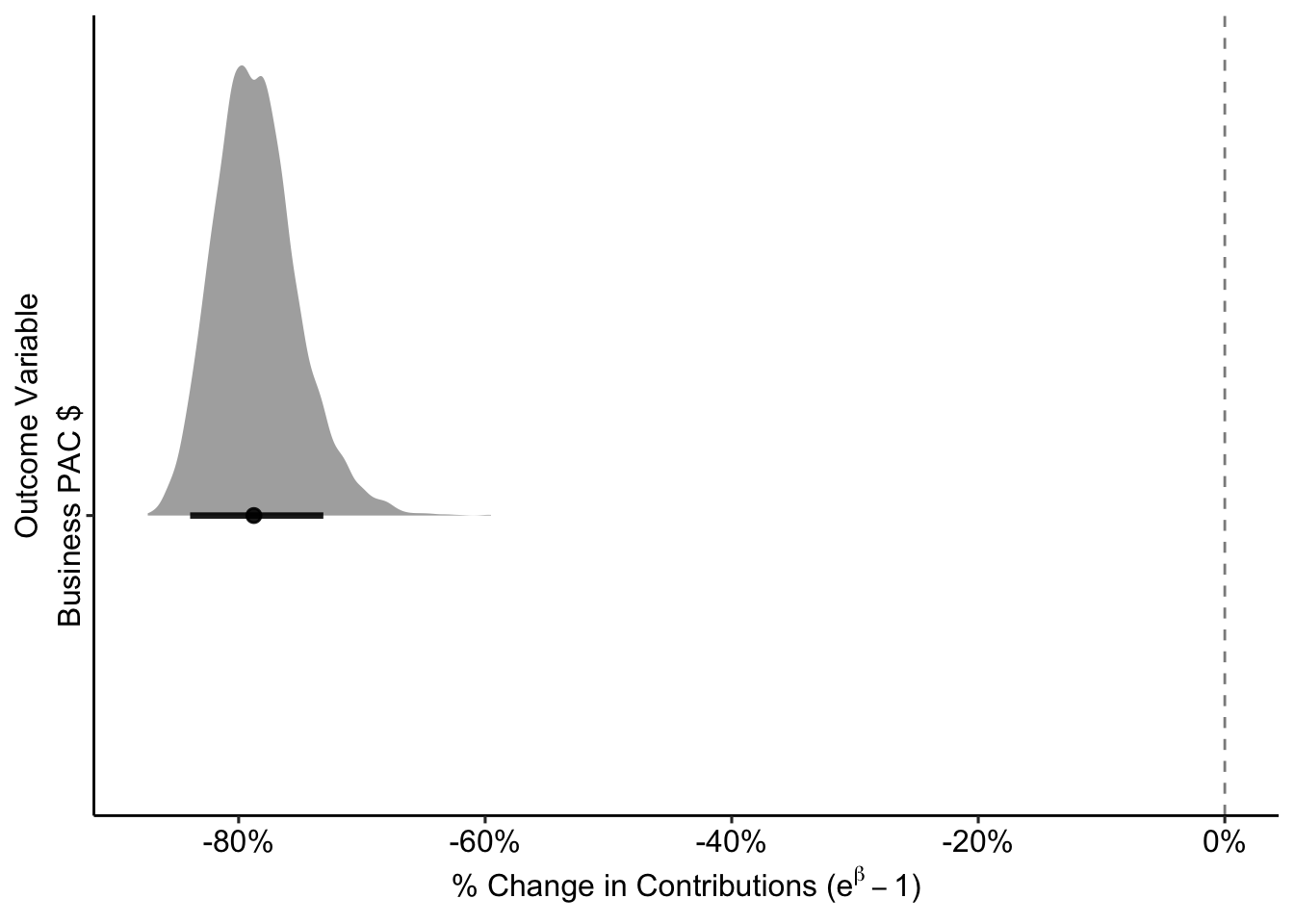
ggsave("Figures/Results/pac_gamma_coef.pdf", height = 4, width = 7)
# Binomial Likelihood ---------------------------------------------------------
biz.pac.coef <-
biz.pac.fit %>%
spread_draws(b_hu_no_corp_pacsYES) %>%
mutate(model = "Business PAC $")
## main effects
library(latex2exp)
biz.pac.coef %>%
mutate(b_np = plogis(b_hu_no_corp_pacsYES)) %>%
ggplot() +
stat_halfeyeh(aes(y = fct_reorder(model, b_np), x = b_np),
.width = c(0.9),
point_interval = median_hdi,
fill = "#A4A4A4",
color = "black",
alpha = 0.9) +
geom_vline(aes(xintercept = 0), linetype = "dashed", color = "grey55") +
scale_x_continuous(labels = percent_format(),
breaks = pretty_breaks(n = 6)) +
labs(x = TeX("Probability of Not Receiving Contributions ($logit^{-1}(\\beta)$)"),
y = "Outcome Variable") +
theme_pubr()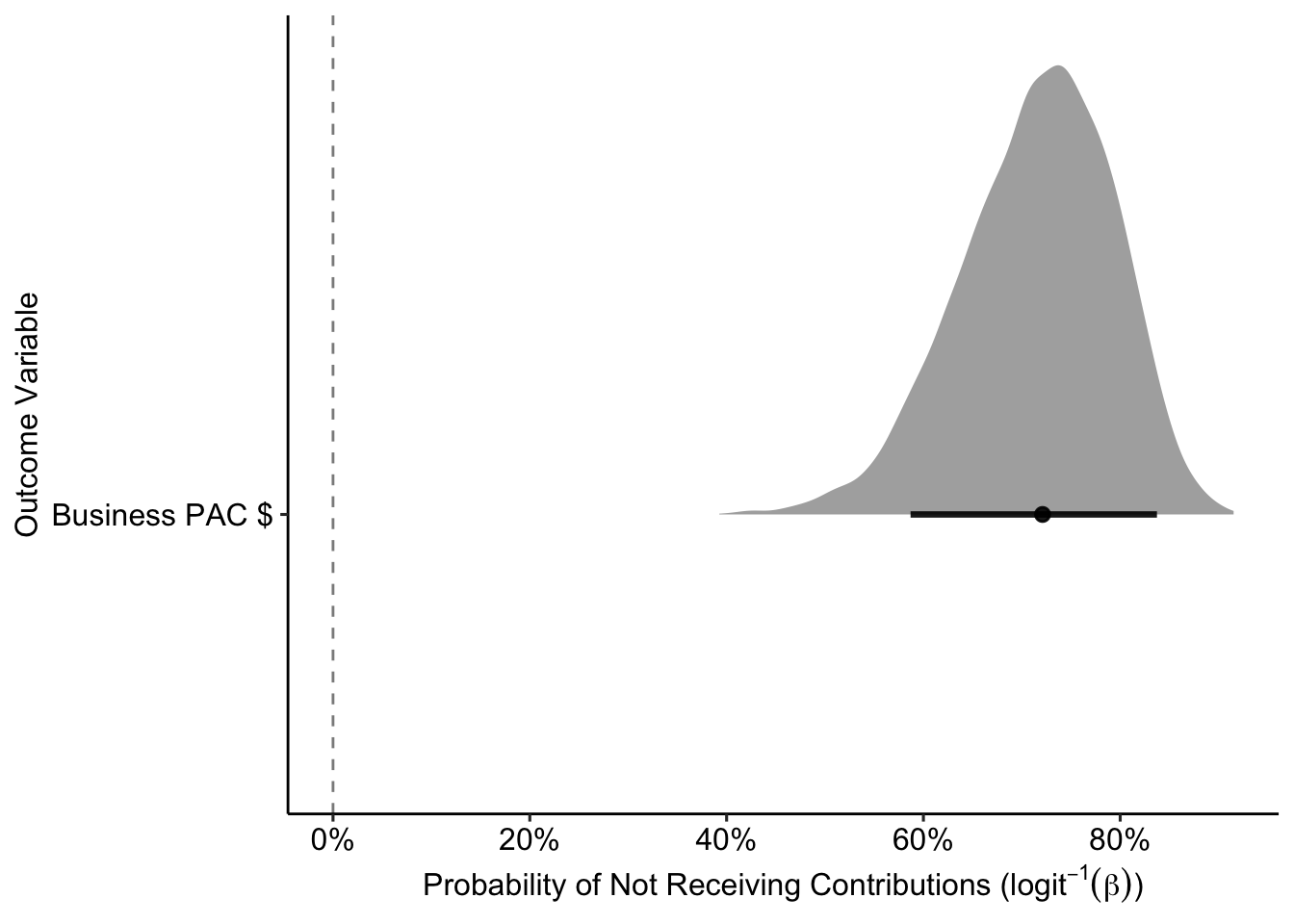
ggsave("Figures/Results/pac_binom_coef.pdf", height = 4, width = 7) Individual Models
Model Fitting
small.indv.fit <- brm(small_indiv ~ no_corp_pacs + new_member + pct_white_c +
pct_black_c + pct_latino_c + pct_asian_c +
pct_bachelors_c + pct_clinton_16_c +
pct_dem_house_16_c + log_tot_voting_age_c +
log_median_hh_income_c,
family = Gamma(link = "log"),
prior = c(prior(normal(13, 13), class = Intercept),
prior(normal(0.2, 0.5), class = b,
coef = "no_corp_pacsYES"),
prior(normal(0, 0.5), class = b)),
sample_prior = "yes",
cores = 4,
iter = 4000,
backend = "cmdstan",
silent = 2,
refresh = 0,
data = estimation.data)## Running MCMC with 4 parallel chains...
##
## Chain 1 finished in 1.0 seconds.
## Chain 2 finished in 1.0 seconds.
## Chain 3 finished in 1.1 seconds.
## Chain 4 finished in 1.0 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 1.0 seconds.
## Total execution time: 1.1 seconds.describe_posterior(small.indv.fit, ci = 0.9, ci_method = "hdi",
test = c("p_direction"))## Summary of Posterior Distribution
##
## Parameter | Median | 90% CI | pd | Rhat | ESS
## ------------------------------------------------------------------------------
## (Intercept) | 11.73 | [11.57, 11.87] | 100% | 1.000 | 11359.00
## no_corp_pacsYES | 1.03 | [ 0.68, 1.34] | 100% | 1.000 | 10007.00
## new_memberYES | 0.70 | [ 0.37, 1.01] | 99.95% | 1.000 | 10124.00
## pct_white_c | 0.25 | [-0.33, 0.82] | 76.34% | 1.000 | 5431.00
## pct_black_c | -0.34 | [-0.82, 0.12] | 88.46% | 1.000 | 4686.00
## pct_latino_c | -0.13 | [-0.59, 0.35] | 67.75% | 1.000 | 5255.00
## pct_asian_c | 5.16e-03 | [-0.37, 0.38] | 50.74% | 1.000 | 6374.00
## pct_bachelors_c | 0.56 | [ 0.13, 0.97] | 98.66% | 1.001 | 6422.00
## pct_clinton_16_c | 3.29e-03 | [-0.48, 0.45] | 50.51% | 1.000 | 6814.00
## pct_dem_house_16_c | -0.21 | [-0.60, 0.16] | 81.77% | 1.000 | 8129.00
## log_tot_voting_age_c | 0.27 | [-0.03, 0.57] | 92.54% | 1.000 | 9471.00
## log_median_hh_income_c | -0.07 | [-0.50, 0.34] | 61.26% | 1.000 | 7395.00
##
## # Fixed effects priors
##
## Parameter | Rhat | ESS
## ---------------------------
## shape | 1.000 | 8149.00
## shape | 1.000 | 8149.00biz.indv.fit <- brm(biz_contribs ~ no_corp_pacs + new_member + pct_white_c +
pct_black_c + pct_latino_c + pct_asian_c +
pct_bachelors_c + pct_clinton_16_c + pct_dem_house_16_c +
log_tot_voting_age_c + log_median_hh_income_c,
family = Gamma(link = "log"),
prior = c(prior(normal(13, 13), class = Intercept),
prior(normal(0, 0.5), class = b)),
sample_prior = "yes",
cores = 4,
iter = 4000,
backend = "cmdstan",
silent = 2,
refresh = 0,
data = estimation.data)## Running MCMC with 4 parallel chains...
##
## Chain 2 finished in 1.0 seconds.
## Chain 1 finished in 1.1 seconds.
## Chain 3 finished in 1.1 seconds.
## Chain 4 finished in 1.1 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 1.1 seconds.
## Total execution time: 1.2 seconds.describe_posterior(biz.indv.fit, ci = 0.9, ci_method = "hdi",
test = c("p_direction"))## Summary of Posterior Distribution
##
## Parameter | Median | 90% CI | pd | Rhat | ESS
## ----------------------------------------------------------------------------
## (Intercept) | 12.28 | [12.18, 12.39] | 100% | 1.000 | 11007.00
## no_corp_pacsYES | 0.39 | [ 0.15, 0.65] | 99.59% | 1.000 | 6979.00
## new_memberYES | 0.51 | [ 0.26, 0.75] | 99.99% | 1.000 | 6594.00
## pct_white_c | 0.09 | [-0.46, 0.62] | 61.15% | 1.000 | 3378.00
## pct_black_c | -0.21 | [-0.64, 0.19] | 79.65% | 1.000 | 3378.00
## pct_latino_c | 0.31 | [-0.13, 0.73] | 88.05% | 1.000 | 3435.00
## pct_asian_c | 0.07 | [-0.22, 0.34] | 65.30% | 1.000 | 4683.00
## pct_bachelors_c | 0.13 | [-0.19, 0.44] | 75.14% | 1.000 | 4841.00
## pct_clinton_16_c | -0.36 | [-0.72, 0.01] | 94.71% | 1.001 | 5237.00
## pct_dem_house_16_c | -0.20 | [-0.49, 0.08] | 88.11% | 1.001 | 6142.00
## log_tot_voting_age_c | 0.01 | [-0.18, 0.22] | 55.02% | 1.000 | 8321.00
## log_median_hh_income_c | 0.50 | [ 0.19, 0.79] | 99.60% | 1.000 | 5920.00
##
## # Fixed effects priors
##
## Parameter | Rhat | ESS
## ---------------------------
## shape | 1.000 | 7623.00
## shape | 1.000 | 7623.00out.dist.biz.fit <- brm(bf(out_of_dist_biz_contrib ~ no_corp_pacs + new_member +
pct_white_c + pct_black_c + pct_latino_c +
pct_asian_c + pct_bachelors_c + pct_clinton_16_c +
pct_dem_house_16_c + log_tot_voting_age_c +
log_median_hh_income_c,
hu ~ no_corp_pacs + new_member),
family = hurdle_gamma(link = "log", link_hu = "logit"),
prior = c(prior(normal(13, 13), class = Intercept),
prior(normal(0, 0.5), class = b),
prior(normal(0, 1), dpar = "hu", class = Intercept),
prior(normal(0, 0.5), dpar = "hu", class = b)),
sample_prior = "yes",
cores = 4,
iter = 4000,
backend = "cmdstan",
silent = 2,
refresh = 0,
data = estimation.data)## Running MCMC with 4 parallel chains...
##
## Chain 1 finished in 3.2 seconds.
## Chain 2 finished in 3.3 seconds.
## Chain 3 finished in 3.5 seconds.
## Chain 4 finished in 3.8 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 3.4 seconds.
## Total execution time: 3.9 seconds.describe_posterior(out.dist.biz.fit, ci = 0.9, ci_method = "hdi",
test = c("p_direction"))## Summary of Posterior Distribution
##
## Parameter | Median | 90% CI | pd | Rhat | ESS
## -------------------------------------------------------------------------------
## (Intercept) | 11.92 | [11.81, 12.05] | 100% | 1.000 | 10659.00
## hu_Intercept | -4.07 | [-4.87, -3.31] | 100% | 1.000 | 9209.00
## no_corp_pacsYES | 0.43 | [ 0.14, 0.70] | 99.55% | 1.000 | 8579.00
## new_memberYES | 0.59 | [ 0.32, 0.88] | 99.96% | 1.000 | 8155.00
## pct_white_c | -0.03 | [-0.60, 0.51] | 53.86% | 1.001 | 4271.00
## pct_black_c | -0.19 | [-0.65, 0.22] | 76.81% | 1.000 | 4306.00
## pct_latino_c | 0.25 | [-0.22, 0.67] | 82.75% | 1.000 | 4351.00
## pct_asian_c | 0.21 | [-0.11, 0.53] | 85.52% | 1.000 | 5778.00
## pct_bachelors_c | -0.03 | [-0.38, 0.33] | 55.30% | 1.000 | 5715.00
## pct_clinton_16_c | -0.38 | [-0.77, 0.03] | 94.19% | 1.000 | 6177.00
## pct_dem_house_16_c | -0.24 | [-0.58, 0.07] | 88.66% | 1.000 | 7325.00
## log_tot_voting_age_c | 0.07 | [-0.15, 0.32] | 70.76% | 1.000 | 8610.00
## log_median_hh_income_c | 0.43 | [ 0.12, 0.79] | 98.32% | 1.000 | 6943.00
## hu_no_corp_pacsYES | -8.30e-03 | [-0.75, 0.78] | 50.78% | 1.000 | 11722.00
## hu_new_memberYES | 5.93e-04 | [-0.73, 0.77] | 50.05% | 1.000 | 11967.00
##
## # Fixed effects priors
##
## Parameter | Rhat | ESS
## ---------------------------
## shape | 1.000 | 8063.00
## shape | 1.000 | 8063.00Model Diagnostics
Prior Influence
# small individual contributions ----------------------------------------------
small.indiv.priors <- prior_samples(small.indv.fit)
small.indiv.post <- posterior_samples(small.indv.fit)
ggplot() +
geom_density(data = small.indiv.priors, aes(x = b_no_corp_pacsYES)) +
geom_density(data = small.indiv.post, aes(x = b_no_corp_pacsYES))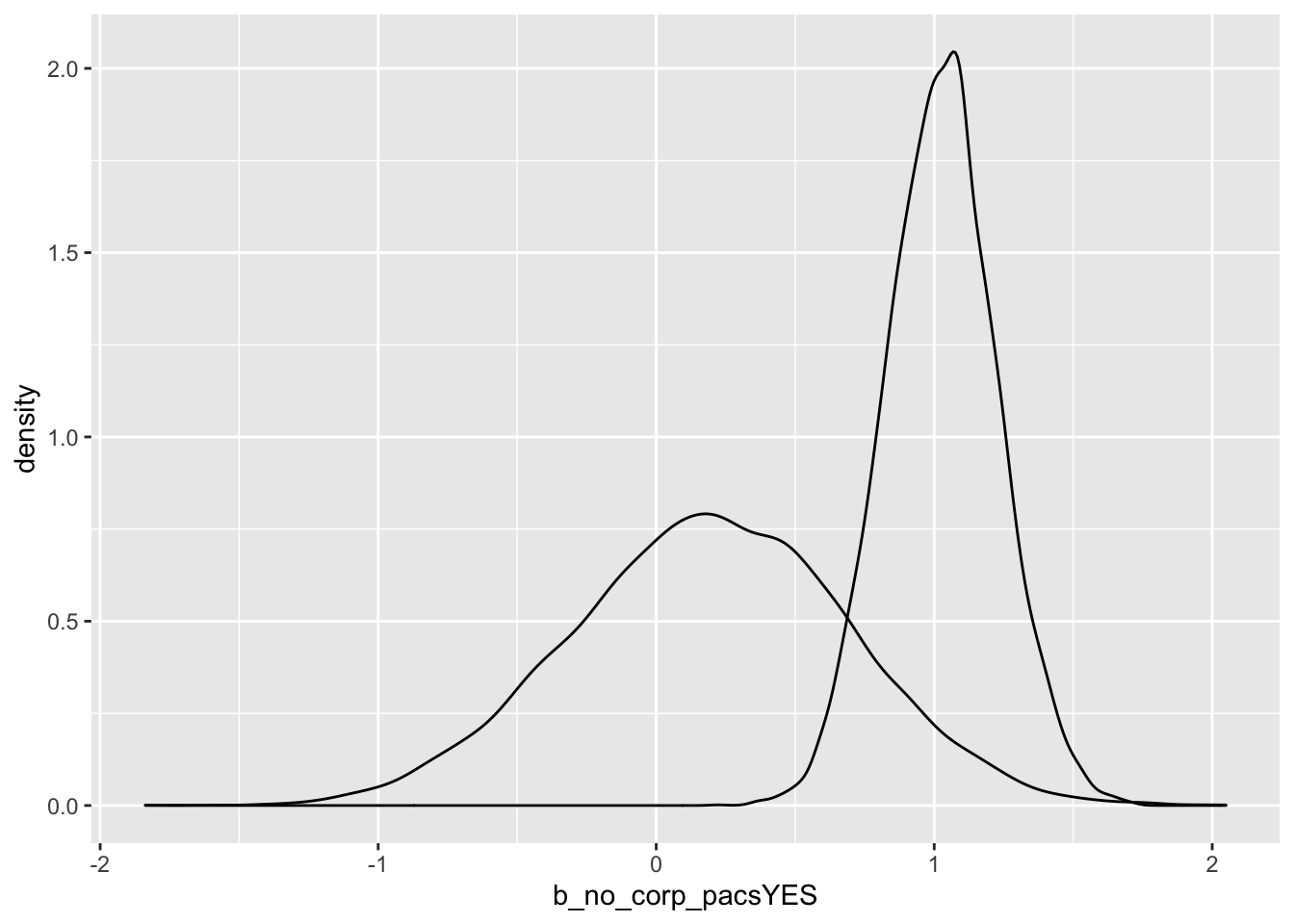
# business individual contributions -------------------------------------------
biz.indv.priors <- prior_samples(biz.indv.fit)
biz.indv.post <- posterior_samples(biz.indv.fit)
ggplot() +
geom_density(data = biz.indv.priors, aes(x = b)) +
geom_density(data = biz.indv.post, aes(x = b_no_corp_pacsYES))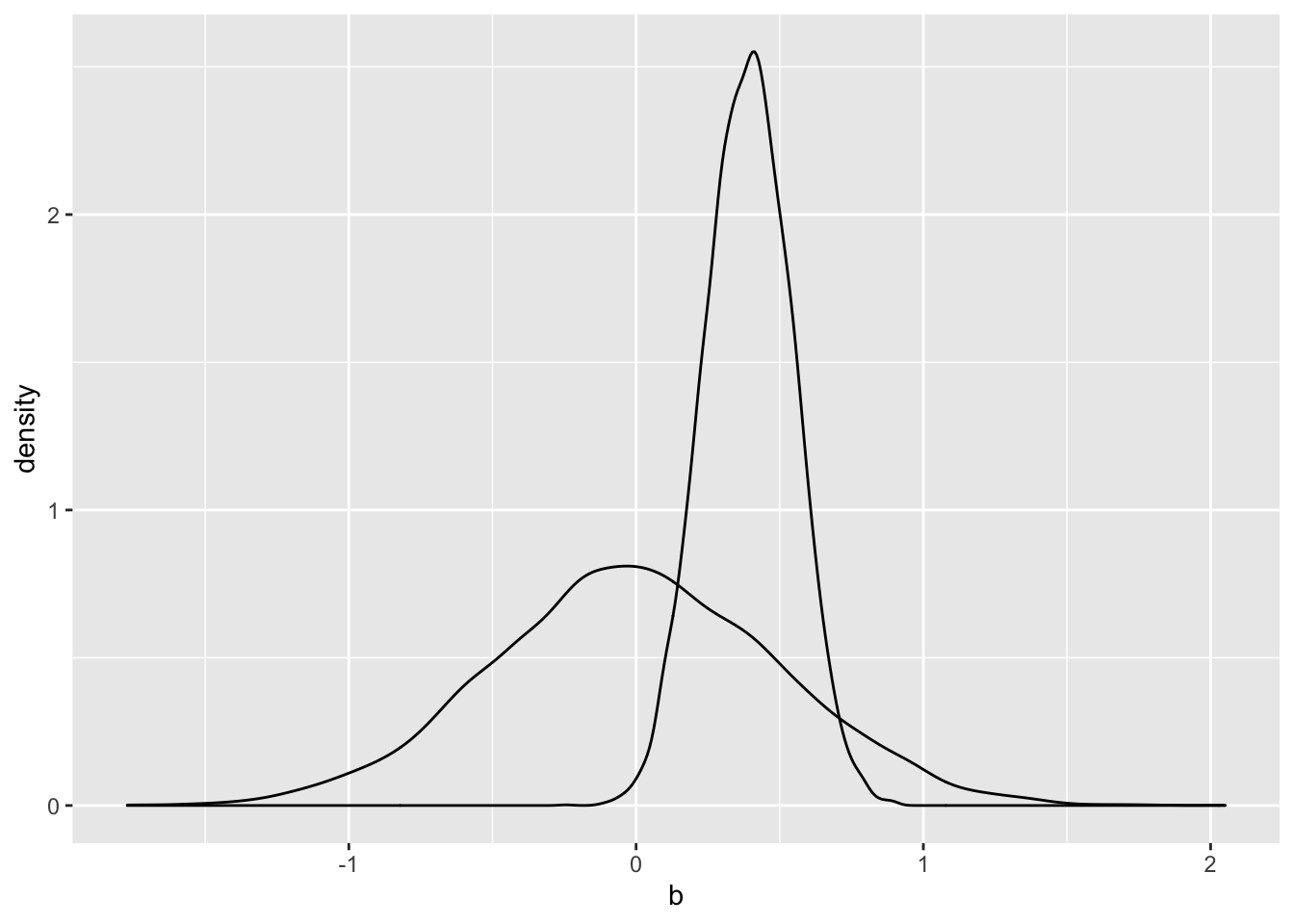
# business individual contributions from out-of-district ----------------------
out.biz.indv.priors <- prior_samples(out.dist.biz.fit)
out.biz.indv.post <- posterior_samples(out.dist.biz.fit)
ggplot() +
geom_density(data = out.biz.indv.priors, aes(x = b)) +
geom_density(data = out.biz.indv.post, aes(x = b_no_corp_pacsYES))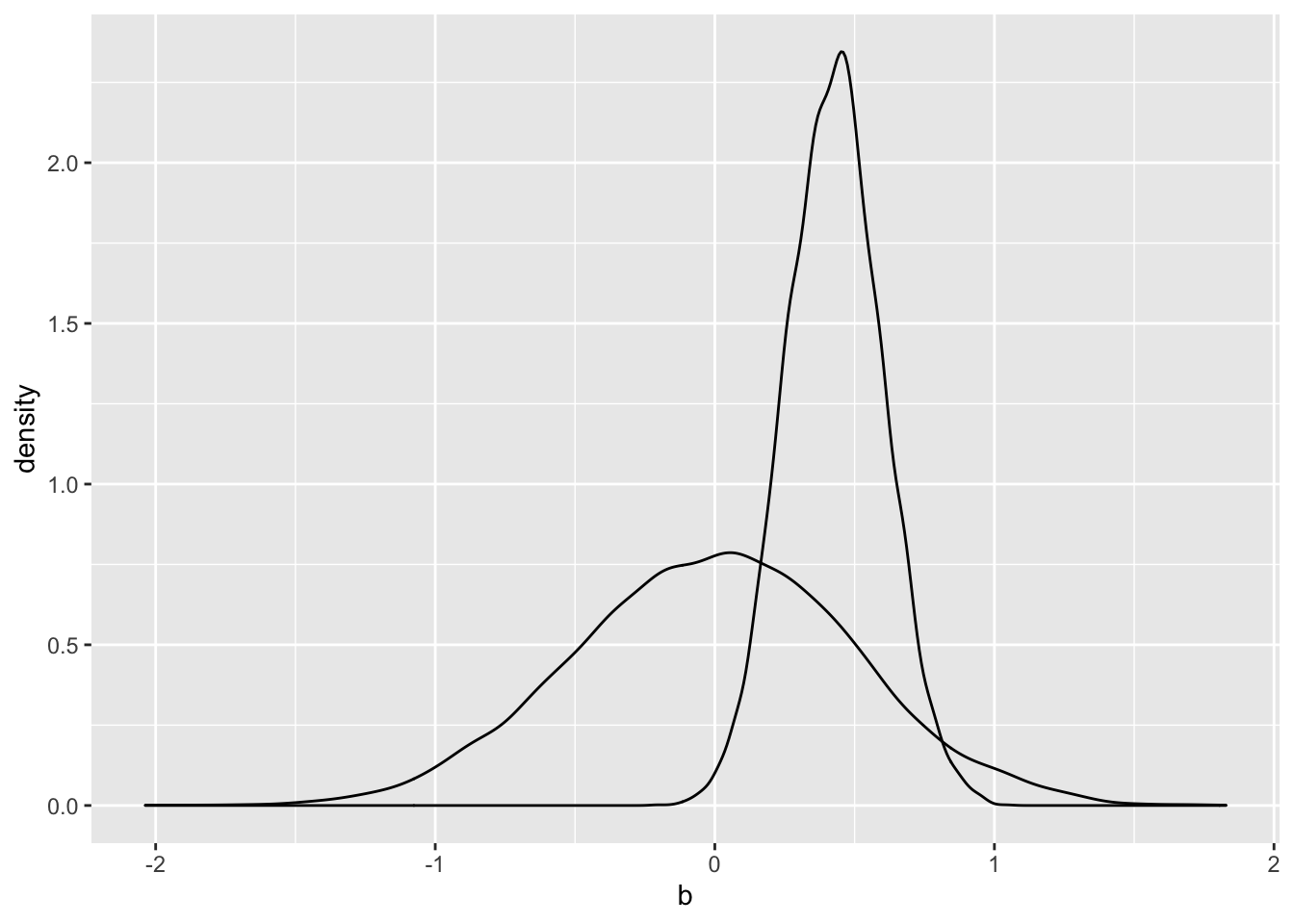
Posterior Predictive Checks
# # small individual contributions --------------------------------------------
y.small.indv <-
estimation.data %>%
pull(small_indiv)
# extract the fitted values
y.rep <- posterior_predict(small.indv.fit, draws = 500)
dim(y.rep)## [1] 8000 221ppc_dens_overlay(y = y.small.indv[1:ncol(y.rep)], yrep = y.rep[1:100, ]) +
xlim(0, 400000)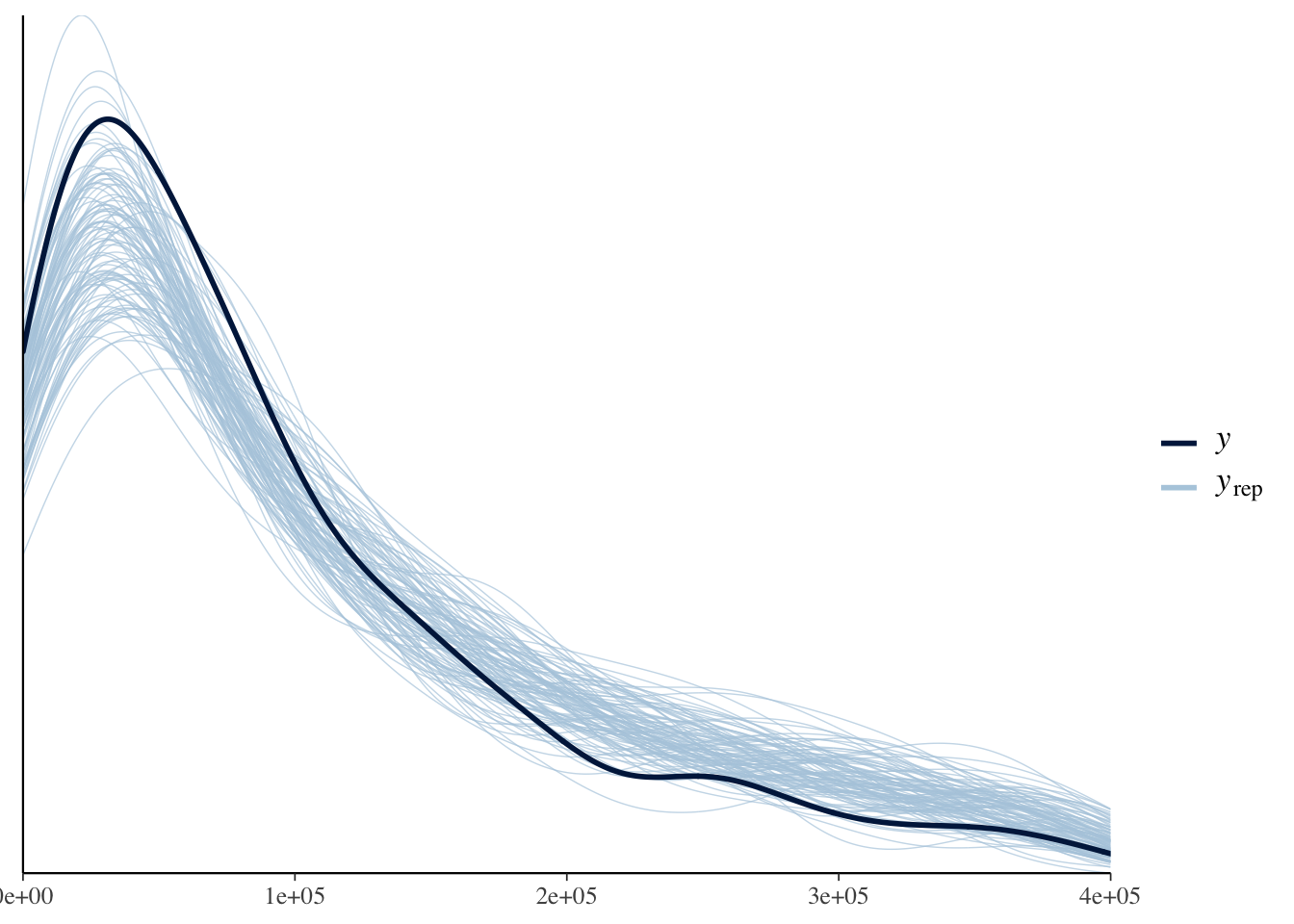
# business individual contributions -------------------------------------------
y.biz.indv <-
estimation.data %>%
pull(biz_contribs)
# extract the fitted values
y.rep <- posterior_predict(biz.indv.fit, draws = 500)
dim(y.rep)## [1] 8000 221ppc_dens_overlay(y = y.biz.indv[1:ncol(y.rep)], yrep = y.rep[1:100, ]) +
xlim(0, 5000000)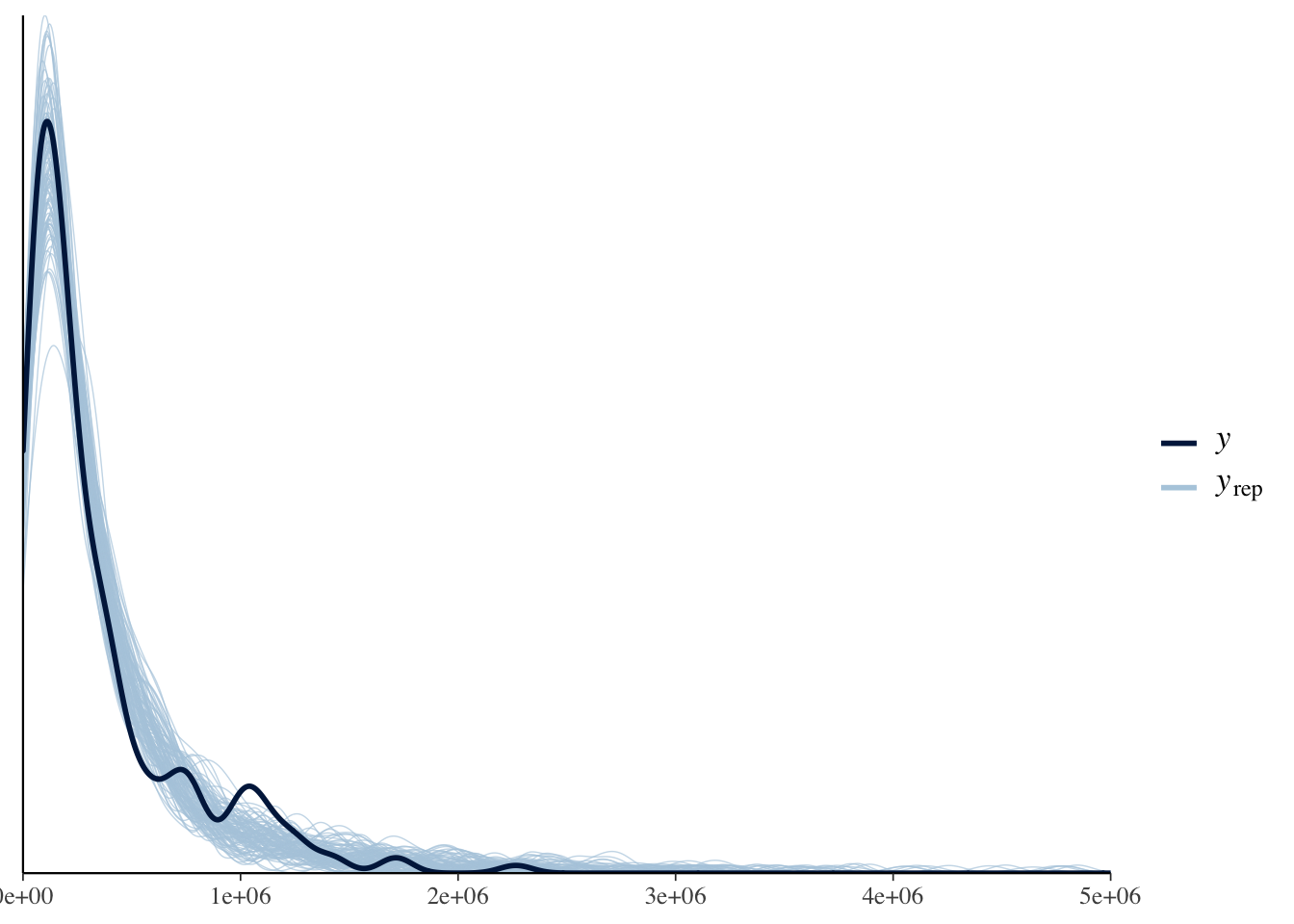
Model Results
Results Tables
Coefficient Plots
# Gamma Likelihood ------------------------------------------------------------
# extract posterior predictions
small.indv.coef <-
small.indv.fit %>%
spread_draws(b_no_corp_pacsYES) %>%
mutate(model = "Small Indiv. $")
biz.indv.coef <-
biz.indv.fit %>%
spread_draws(b_no_corp_pacsYES) %>%
mutate(model = "Business Indiv. $")
out.biz.indv.coef <-
out.dist.biz.fit %>%
spread_draws(b_no_corp_pacsYES) %>%
mutate(model = "Out-of-District Business Indiv. $")
indv.models <-
bind_rows(small.indv.coef, biz.indv.coef, out.biz.indv.coef) %>%
mutate(b_np = exp(b_no_corp_pacsYES) - 1)
## main effects
library(latex2exp)
indv.models %>%
#filter(model == "Out-of-District Business Indiv. $") %>%
ggplot() +
stat_halfeyeh(aes(y = fct_reorder(model, b_np), x = b_np),
.width = c(0.9),
point_interval = median_hdi,
fill = "#A4A4A4",
color = "black",
alpha = 0.9) +
geom_vline(aes(xintercept = 0), linetype = "dashed", color = "grey55") +
scale_x_continuous(labels = percent_format(),
breaks = pretty_breaks(n = 6)) +
labs(x = TeX("% Change in Contributions ($\\e^{\\beta} - 1$)"),
y = "Outcome Variable") +
theme_pubr()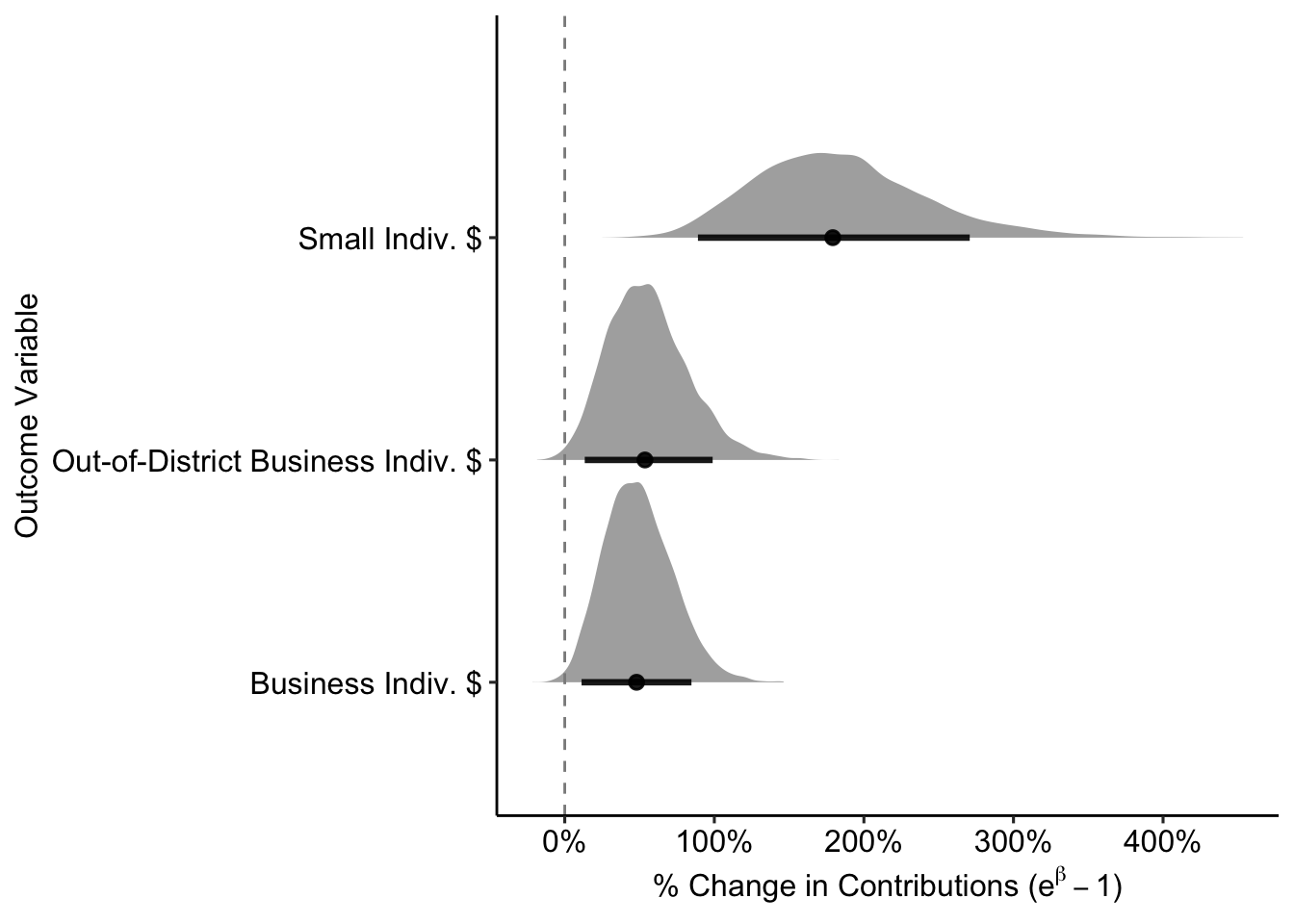
ggsave("Figures/Results/indv_gamma_coef.pdf", height = 4, width = 7)
# Binomial Likelihood ---------------------------------------------------------
out.biz.indv.coef <-
out.dist.biz.fit %>%
spread_draws(b_hu_no_corp_pacsYES) %>%
mutate(model = "Out-of-District Business Indiv. $")
## main effects
library(latex2exp)
out.biz.indv.coef %>%
rename(b_np = b_hu_no_corp_pacsYES) %>%
ggplot() +
stat_halfeyeh(aes(y = fct_reorder(model, b_np), x = b_np),
.width = c(0.9),
point_interval = median_hdi,
fill = "#A4A4A4",
color = "black",
alpha = 0.9) +
geom_vline(aes(xintercept = 0), linetype = "dashed", color = "grey55") +
scale_x_continuous(labels = percent_format(),
breaks = pretty_breaks(n = 4)) +
labs(x = TeX("Probability of Not Receiving Contributions ($logit^{-1}(\\beta)$)"),
y = "Outcome Variable") +
theme_pubr()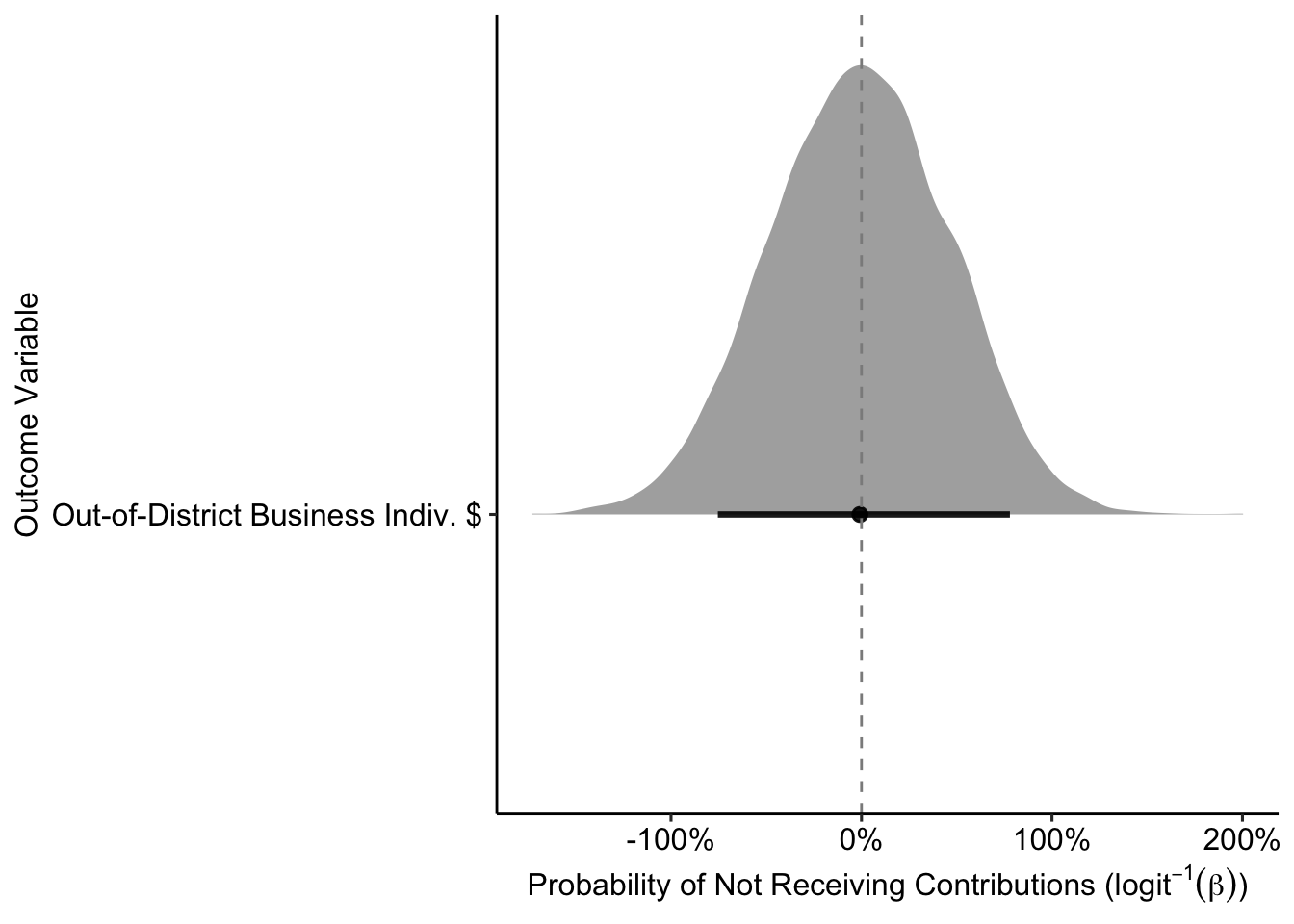
ggsave("Figures/Results/indv_binom_coef.pdf", height = 4, width = 7) Proportion Models
estimation.data <-
estimation.data %>%
mutate(tot_contribs = business_pacs + small_indiv + biz_contribs +
out_of_dist_biz_contrib,
biz_pac_prop = business_pacs / tot_contribs,
small_indiv_prop = small_indiv / tot_contribs,
biz_contribs_prop = biz_contribs / tot_contribs,
out_of_dist_biz_contrib_prop = out_of_dist_biz_contrib / tot_contribs,
sum = biz_pac_prop + biz_contribs_prop + small_indiv_prop +
out_of_dist_biz_contrib_prop)
dir.estimation.data <-
estimation.data %>%
filter(biz_pac_prop != 0) %>%
filter(small_indiv_prop != 0) %>%
filter(biz_contribs_prop != 0) %>%
filter(out_of_dist_biz_contrib_prop != 0)
dir.estimation.data$y <-
with(dir.estimation.data, cbind(biz_pac_prop, small_indiv_prop,
biz_contribs_prop,
out_of_dist_biz_contrib_prop))
dir.fit <- brm(y ~ no_corp_pacs + new_member + pct_white_c +
pct_black_c + pct_latino_c + pct_asian_c +
pct_bachelors_c + pct_clinton_16_c + vote_margin +
pct_dem_house_16_c + log_tot_voting_age_c +
log_median_hh_income_c,
family = dirichlet(link = "logit"),
cores = 4,
iter = 4000,
backend = "cmdstanr",
data = dir.estimation.data)## Running MCMC with 4 parallel chains...
##
## Chain 1 Iteration: 1 / 4000 [ 0%] (Warmup)
## Chain 2 Iteration: 1 / 4000 [ 0%] (Warmup)
## Chain 3 Iteration: 1 / 4000 [ 0%] (Warmup)
## Chain 4 Iteration: 1 / 4000 [ 0%] (Warmup)
## Chain 4 Iteration: 100 / 4000 [ 2%] (Warmup)
## Chain 2 Iteration: 100 / 4000 [ 2%] (Warmup)
## Chain 1 Iteration: 100 / 4000 [ 2%] (Warmup)
## Chain 3 Iteration: 100 / 4000 [ 2%] (Warmup)
## Chain 2 Iteration: 200 / 4000 [ 5%] (Warmup)
## Chain 4 Iteration: 200 / 4000 [ 5%] (Warmup)
## Chain 1 Iteration: 200 / 4000 [ 5%] (Warmup)
## Chain 3 Iteration: 200 / 4000 [ 5%] (Warmup)
## Chain 2 Iteration: 300 / 4000 [ 7%] (Warmup)
## Chain 4 Iteration: 300 / 4000 [ 7%] (Warmup)
## Chain 3 Iteration: 300 / 4000 [ 7%] (Warmup)
## Chain 1 Iteration: 300 / 4000 [ 7%] (Warmup)
## Chain 2 Iteration: 400 / 4000 [ 10%] (Warmup)
## Chain 4 Iteration: 400 / 4000 [ 10%] (Warmup)
## Chain 3 Iteration: 400 / 4000 [ 10%] (Warmup)
## Chain 1 Iteration: 400 / 4000 [ 10%] (Warmup)
## Chain 2 Iteration: 500 / 4000 [ 12%] (Warmup)
## Chain 4 Iteration: 500 / 4000 [ 12%] (Warmup)
## Chain 3 Iteration: 500 / 4000 [ 12%] (Warmup)
## Chain 2 Iteration: 600 / 4000 [ 15%] (Warmup)
## Chain 1 Iteration: 500 / 4000 [ 12%] (Warmup)
## Chain 4 Iteration: 600 / 4000 [ 15%] (Warmup)
## Chain 3 Iteration: 600 / 4000 [ 15%] (Warmup)
## Chain 2 Iteration: 700 / 4000 [ 17%] (Warmup)
## Chain 4 Iteration: 700 / 4000 [ 17%] (Warmup)
## Chain 1 Iteration: 600 / 4000 [ 15%] (Warmup)
## Chain 3 Iteration: 700 / 4000 [ 17%] (Warmup)
## Chain 2 Iteration: 800 / 4000 [ 20%] (Warmup)
## Chain 4 Iteration: 800 / 4000 [ 20%] (Warmup)
## Chain 1 Iteration: 700 / 4000 [ 17%] (Warmup)
## Chain 3 Iteration: 800 / 4000 [ 20%] (Warmup)
## Chain 2 Iteration: 900 / 4000 [ 22%] (Warmup)
## Chain 4 Iteration: 900 / 4000 [ 22%] (Warmup)
## Chain 1 Iteration: 800 / 4000 [ 20%] (Warmup)
## Chain 3 Iteration: 900 / 4000 [ 22%] (Warmup)
## Chain 2 Iteration: 1000 / 4000 [ 25%] (Warmup)
## Chain 4 Iteration: 1000 / 4000 [ 25%] (Warmup)
## Chain 1 Iteration: 900 / 4000 [ 22%] (Warmup)
## Chain 3 Iteration: 1000 / 4000 [ 25%] (Warmup)
## Chain 2 Iteration: 1100 / 4000 [ 27%] (Warmup)
## Chain 4 Iteration: 1100 / 4000 [ 27%] (Warmup)
## Chain 1 Iteration: 1000 / 4000 [ 25%] (Warmup)
## Chain 3 Iteration: 1100 / 4000 [ 27%] (Warmup)
## Chain 2 Iteration: 1200 / 4000 [ 30%] (Warmup)
## Chain 4 Iteration: 1200 / 4000 [ 30%] (Warmup)
## Chain 1 Iteration: 1100 / 4000 [ 27%] (Warmup)
## Chain 3 Iteration: 1200 / 4000 [ 30%] (Warmup)
## Chain 2 Iteration: 1300 / 4000 [ 32%] (Warmup)
## Chain 4 Iteration: 1300 / 4000 [ 32%] (Warmup)
## Chain 1 Iteration: 1200 / 4000 [ 30%] (Warmup)
## Chain 3 Iteration: 1300 / 4000 [ 32%] (Warmup)
## Chain 2 Iteration: 1400 / 4000 [ 35%] (Warmup)
## Chain 4 Iteration: 1400 / 4000 [ 35%] (Warmup)
## Chain 3 Iteration: 1400 / 4000 [ 35%] (Warmup)
## Chain 1 Iteration: 1300 / 4000 [ 32%] (Warmup)
## Chain 2 Iteration: 1500 / 4000 [ 37%] (Warmup)
## Chain 4 Iteration: 1500 / 4000 [ 37%] (Warmup)
## Chain 3 Iteration: 1500 / 4000 [ 37%] (Warmup)
## Chain 1 Iteration: 1400 / 4000 [ 35%] (Warmup)
## Chain 2 Iteration: 1600 / 4000 [ 40%] (Warmup)
## Chain 4 Iteration: 1600 / 4000 [ 40%] (Warmup)
## Chain 3 Iteration: 1600 / 4000 [ 40%] (Warmup)
## Chain 1 Iteration: 1500 / 4000 [ 37%] (Warmup)
## Chain 2 Iteration: 1700 / 4000 [ 42%] (Warmup)
## Chain 4 Iteration: 1700 / 4000 [ 42%] (Warmup)
## Chain 3 Iteration: 1700 / 4000 [ 42%] (Warmup)
## Chain 2 Iteration: 1800 / 4000 [ 45%] (Warmup)
## Chain 1 Iteration: 1600 / 4000 [ 40%] (Warmup)
## Chain 4 Iteration: 1800 / 4000 [ 45%] (Warmup)
## Chain 3 Iteration: 1800 / 4000 [ 45%] (Warmup)
## Chain 2 Iteration: 1900 / 4000 [ 47%] (Warmup)
## Chain 1 Iteration: 1700 / 4000 [ 42%] (Warmup)
## Chain 4 Iteration: 1900 / 4000 [ 47%] (Warmup)
## Chain 3 Iteration: 1900 / 4000 [ 47%] (Warmup)
## Chain 1 Iteration: 1800 / 4000 [ 45%] (Warmup)
## Chain 2 Iteration: 2000 / 4000 [ 50%] (Warmup)
## Chain 2 Iteration: 2001 / 4000 [ 50%] (Sampling)
## Chain 3 Iteration: 2000 / 4000 [ 50%] (Warmup)
## Chain 3 Iteration: 2001 / 4000 [ 50%] (Sampling)
## Chain 4 Iteration: 2000 / 4000 [ 50%] (Warmup)
## Chain 4 Iteration: 2001 / 4000 [ 50%] (Sampling)
## Chain 1 Iteration: 1900 / 4000 [ 47%] (Warmup)
## Chain 2 Iteration: 2100 / 4000 [ 52%] (Sampling)
## Chain 3 Iteration: 2100 / 4000 [ 52%] (Sampling)
## Chain 1 Iteration: 2000 / 4000 [ 50%] (Warmup)
## Chain 1 Iteration: 2001 / 4000 [ 50%] (Sampling)
## Chain 4 Iteration: 2100 / 4000 [ 52%] (Sampling)
## Chain 2 Iteration: 2200 / 4000 [ 55%] (Sampling)
## Chain 1 Iteration: 2100 / 4000 [ 52%] (Sampling)
## Chain 3 Iteration: 2200 / 4000 [ 55%] (Sampling)
## Chain 4 Iteration: 2200 / 4000 [ 55%] (Sampling)
## Chain 2 Iteration: 2300 / 4000 [ 57%] (Sampling)
## Chain 1 Iteration: 2200 / 4000 [ 55%] (Sampling)
## Chain 3 Iteration: 2300 / 4000 [ 57%] (Sampling)
## Chain 4 Iteration: 2300 / 4000 [ 57%] (Sampling)
## Chain 1 Iteration: 2300 / 4000 [ 57%] (Sampling)
## Chain 2 Iteration: 2400 / 4000 [ 60%] (Sampling)
## Chain 3 Iteration: 2400 / 4000 [ 60%] (Sampling)
## Chain 1 Iteration: 2400 / 4000 [ 60%] (Sampling)
## Chain 4 Iteration: 2400 / 4000 [ 60%] (Sampling)
## Chain 2 Iteration: 2500 / 4000 [ 62%] (Sampling)
## Chain 3 Iteration: 2500 / 4000 [ 62%] (Sampling)
## Chain 1 Iteration: 2500 / 4000 [ 62%] (Sampling)
## Chain 2 Iteration: 2600 / 4000 [ 65%] (Sampling)
## Chain 4 Iteration: 2500 / 4000 [ 62%] (Sampling)
## Chain 3 Iteration: 2600 / 4000 [ 65%] (Sampling)
## Chain 1 Iteration: 2600 / 4000 [ 65%] (Sampling)
## Chain 2 Iteration: 2700 / 4000 [ 67%] (Sampling)
## Chain 3 Iteration: 2700 / 4000 [ 67%] (Sampling)
## Chain 4 Iteration: 2600 / 4000 [ 65%] (Sampling)
## Chain 1 Iteration: 2700 / 4000 [ 67%] (Sampling)
## Chain 2 Iteration: 2800 / 4000 [ 70%] (Sampling)
## Chain 1 Iteration: 2800 / 4000 [ 70%] (Sampling)
## Chain 3 Iteration: 2800 / 4000 [ 70%] (Sampling)
## Chain 4 Iteration: 2700 / 4000 [ 67%] (Sampling)
## Chain 2 Iteration: 2900 / 4000 [ 72%] (Sampling)
## Chain 1 Iteration: 2900 / 4000 [ 72%] (Sampling)
## Chain 3 Iteration: 2900 / 4000 [ 72%] (Sampling)
## Chain 4 Iteration: 2800 / 4000 [ 70%] (Sampling)
## Chain 2 Iteration: 3000 / 4000 [ 75%] (Sampling)
## Chain 1 Iteration: 3000 / 4000 [ 75%] (Sampling)
## Chain 3 Iteration: 3000 / 4000 [ 75%] (Sampling)
## Chain 4 Iteration: 2900 / 4000 [ 72%] (Sampling)
## Chain 1 Iteration: 3100 / 4000 [ 77%] (Sampling)
## Chain 2 Iteration: 3100 / 4000 [ 77%] (Sampling)
## Chain 3 Iteration: 3100 / 4000 [ 77%] (Sampling)
## Chain 1 Iteration: 3200 / 4000 [ 80%] (Sampling)
## Chain 4 Iteration: 3000 / 4000 [ 75%] (Sampling)
## Chain 2 Iteration: 3200 / 4000 [ 80%] (Sampling)
## Chain 3 Iteration: 3200 / 4000 [ 80%] (Sampling)
## Chain 1 Iteration: 3300 / 4000 [ 82%] (Sampling)
## Chain 2 Iteration: 3300 / 4000 [ 82%] (Sampling)
## Chain 4 Iteration: 3100 / 4000 [ 77%] (Sampling)
## Chain 1 Iteration: 3400 / 4000 [ 85%] (Sampling)
## Chain 3 Iteration: 3300 / 4000 [ 82%] (Sampling)
## Chain 2 Iteration: 3400 / 4000 [ 85%] (Sampling)
## Chain 4 Iteration: 3200 / 4000 [ 80%] (Sampling)
## Chain 1 Iteration: 3500 / 4000 [ 87%] (Sampling)
## Chain 3 Iteration: 3400 / 4000 [ 85%] (Sampling)
## Chain 2 Iteration: 3500 / 4000 [ 87%] (Sampling)
## Chain 4 Iteration: 3300 / 4000 [ 82%] (Sampling)
## Chain 1 Iteration: 3600 / 4000 [ 90%] (Sampling)
## Chain 3 Iteration: 3500 / 4000 [ 87%] (Sampling)
## Chain 2 Iteration: 3600 / 4000 [ 90%] (Sampling)
## Chain 1 Iteration: 3700 / 4000 [ 92%] (Sampling)
## Chain 4 Iteration: 3400 / 4000 [ 85%] (Sampling)
## Chain 3 Iteration: 3600 / 4000 [ 90%] (Sampling)
## Chain 2 Iteration: 3700 / 4000 [ 92%] (Sampling)
## Chain 1 Iteration: 3800 / 4000 [ 95%] (Sampling)
## Chain 3 Iteration: 3700 / 4000 [ 92%] (Sampling)
## Chain 4 Iteration: 3500 / 4000 [ 87%] (Sampling)
## Chain 1 Iteration: 3900 / 4000 [ 97%] (Sampling)
## Chain 2 Iteration: 3800 / 4000 [ 95%] (Sampling)
## Chain 3 Iteration: 3800 / 4000 [ 95%] (Sampling)
## Chain 1 Iteration: 4000 / 4000 [100%] (Sampling)
## Chain 1 finished in 62.7 seconds.
## Chain 4 Iteration: 3600 / 4000 [ 90%] (Sampling)
## Chain 2 Iteration: 3900 / 4000 [ 97%] (Sampling)
## Chain 3 Iteration: 3900 / 4000 [ 97%] (Sampling)
## Chain 4 Iteration: 3700 / 4000 [ 92%] (Sampling)
## Chain 2 Iteration: 4000 / 4000 [100%] (Sampling)
## Chain 2 finished in 64.9 seconds.
## Chain 3 Iteration: 4000 / 4000 [100%] (Sampling)
## Chain 3 finished in 65.7 seconds.
## Chain 4 Iteration: 3800 / 4000 [ 95%] (Sampling)
## Chain 4 Iteration: 3900 / 4000 [ 97%] (Sampling)
## Chain 4 Iteration: 4000 / 4000 [100%] (Sampling)
## Chain 4 finished in 69.9 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 65.8 seconds.
## Total execution time: 70.0 seconds.describe_posterior(dir.fit, ci = 0.9, ci_method = "hdi",
test = c("p_direction"))## Summary of Posterior Distribution
##
## Parameter | Median | 90% CI | pd | Rhat | ESS
## --------------------------------------------------------------------------------------------------------
## musmallindivprop_Intercept | -1.42 | [-1.65, -1.16] | 100% | 1.000 | 8096.00
## mubizcontribsprop_Intercept | -0.68 | [-0.91, -0.47] | 100% | 1.000 | 8215.00
## muoutofdistbizcontribprop_Intercept | -0.99 | [-1.23, -0.74] | 100% | 1.001 | 8843.00
## musmallindivprop_no_corp_pacsYES | 1.76 | [ 1.40, 2.10] | 100% | 1.000 | 6093.00
## musmallindivprop_new_memberYES | 2.47 | [ 2.13, 2.80] | 100% | 1.000 | 5306.00
## musmallindivprop_pct_white_c | -1.73 | [-3.26, -0.29] | 97.02% | 1.000 | 3393.00
## musmallindivprop_pct_black_c | -1.81 | [-2.89, -0.72] | 99.51% | 1.000 | 3441.00
## musmallindivprop_pct_latino_c | -1.48 | [-2.64, -0.35] | 98.06% | 1.000 | 3410.00
## musmallindivprop_pct_asian_c | -0.48 | [-1.09, 0.12] | 90.53% | 1.000 | 3503.00
## musmallindivprop_pct_bachelors_c | 0.45 | [ 0.04, 0.87] | 96.19% | 1.001 | 5384.00
## musmallindivprop_pct_clinton_16_c | 0.15 | [-0.38, 0.62] | 68.24% | 1.000 | 6091.00
## musmallindivprop_vote_margin | -7.03e-03 | [-0.02, 0.00] | 84.86% | 1.000 | 8629.00
## musmallindivprop_pct_dem_house_16_c | -0.10 | [-0.43, 0.20] | 71.17% | 1.000 | 7445.00
## musmallindivprop_log_tot_voting_age_c | 0.18 | [-0.02, 0.38] | 93.33% | 1.001 | 7997.00
## musmallindivprop_log_median_hh_income_c | -0.09 | [-0.47, 0.31] | 64.28% | 1.000 | 6022.00
## mubizcontribsprop_no_corp_pacsYES | 1.31 | [ 0.97, 1.63] | 100% | 1.000 | 6030.00
## mubizcontribsprop_new_memberYES | 2.23 | [ 1.91, 2.53] | 100% | 1.000 | 5560.00
## mubizcontribsprop_pct_white_c | 0.55 | [-1.25, 2.48] | 69.03% | 1.000 | 3286.00
## mubizcontribsprop_pct_black_c | 0.15 | [-1.26, 1.46] | 57.53% | 1.000 | 3308.00
## mubizcontribsprop_pct_latino_c | 0.69 | [-0.69, 2.14] | 79.39% | 1.000 | 3305.00
## mubizcontribsprop_pct_asian_c | 0.47 | [-0.22, 1.24] | 86.21% | 1.000 | 3371.00
## mubizcontribsprop_pct_bachelors_c | 0.29 | [-0.11, 0.65] | 89.24% | 1.001 | 5321.00
## mubizcontribsprop_pct_clinton_16_c | 0.25 | [-0.23, 0.68] | 81.34% | 1.000 | 5947.00
## mubizcontribsprop_vote_margin | -9.17e-03 | [-0.02, 0.00] | 92.77% | 1.000 | 7952.00
## mubizcontribsprop_pct_dem_house_16_c | -0.35 | [-0.63, -0.05] | 97.65% | 1.000 | 7393.00
## mubizcontribsprop_log_tot_voting_age_c | 8.67e-03 | [-0.17, 0.19] | 53.39% | 1.001 | 8036.00
## mubizcontribsprop_log_median_hh_income_c | 0.16 | [-0.18, 0.52] | 77.46% | 1.000 | 5795.00
## muoutofdistbizcontribprop_no_corp_pacsYES | 1.41 | [ 1.05, 1.75] | 100% | 1.000 | 6147.00
## muoutofdistbizcontribprop_new_memberYES | 2.25 | [ 1.94, 2.59] | 100% | 1.000 | 5416.00
## muoutofdistbizcontribprop_pct_white_c | 0.53 | [-1.46, 2.67] | 66.41% | 1.001 | 3070.00
## muoutofdistbizcontribprop_pct_black_c | 0.34 | [-1.12, 1.91] | 64.04% | 1.001 | 3089.00
## muoutofdistbizcontribprop_pct_latino_c | 0.76 | [-0.73, 2.42] | 78.89% | 1.001 | 3083.00
## muoutofdistbizcontribprop_pct_asian_c | 0.58 | [-0.28, 1.39] | 88.35% | 1.001 | 3204.00
## muoutofdistbizcontribprop_pct_bachelors_c | 0.11 | [-0.32, 0.51] | 66.67% | 1.001 | 5262.00
## muoutofdistbizcontribprop_pct_clinton_16_c | 0.29 | [-0.19, 0.82] | 83.12% | 1.001 | 6188.00
## muoutofdistbizcontribprop_vote_margin | -0.01 | [-0.02, 0.00] | 97.15% | 1.001 | 8482.00
## muoutofdistbizcontribprop_pct_dem_house_16_c | -0.45 | [-0.78, -0.12] | 98.81% | 1.001 | 7256.00
## muoutofdistbizcontribprop_log_tot_voting_age_c | 0.11 | [-0.09, 0.31] | 81.54% | 1.001 | 8308.00
## muoutofdistbizcontribprop_log_median_hh_income_c | 0.09 | [-0.29, 0.46] | 64.59% | 1.000 | 5987.00ce <- conditional_effects(dir.fit, categorical = T, effects = "no_corp_pacs",
prob = 0.9, method = "posterior_epred")[[1]]
ggplot(data = ce, aes(x = no_corp_pacs, y = estimate__, ymin = lower__,
ymax = upper__, shape = cats__, color = cats__)) +
#geom_pointinterval(position = position_dodge(width = 0.5), size = 8) +
geom_point(position = position_dodge(width = 0.5), size = 3) +
geom_linerange(position = position_dodge(width = 0.5), width = 3) +
scale_color_manual(values = c("gray62", "gray38", "grey20", "black"),
labels = c("Business PACs", "Small Individual",
"Business Individual",
"Out-of-District Business Indiv.")) +
scale_shape_manual(values = c(15, 19, 17, 18),
labels = c("Business PACs", "Small Individual",
"Business Individual",
"Out-of-District Business Indiv.")) +
labs(x = "Candidate Accepts Corporate PAC Contributions?",
y = "Proportion of Contributions",
color = "Contributions from:",
shape = "Contributions from:") +
scale_x_discrete(labels = c("Yes", "No")) +
scale_y_continuous(labels = percent_format(), limits = c(0, 0.6),
breaks = pretty_breaks(n = 6)) +
theme_pubclean()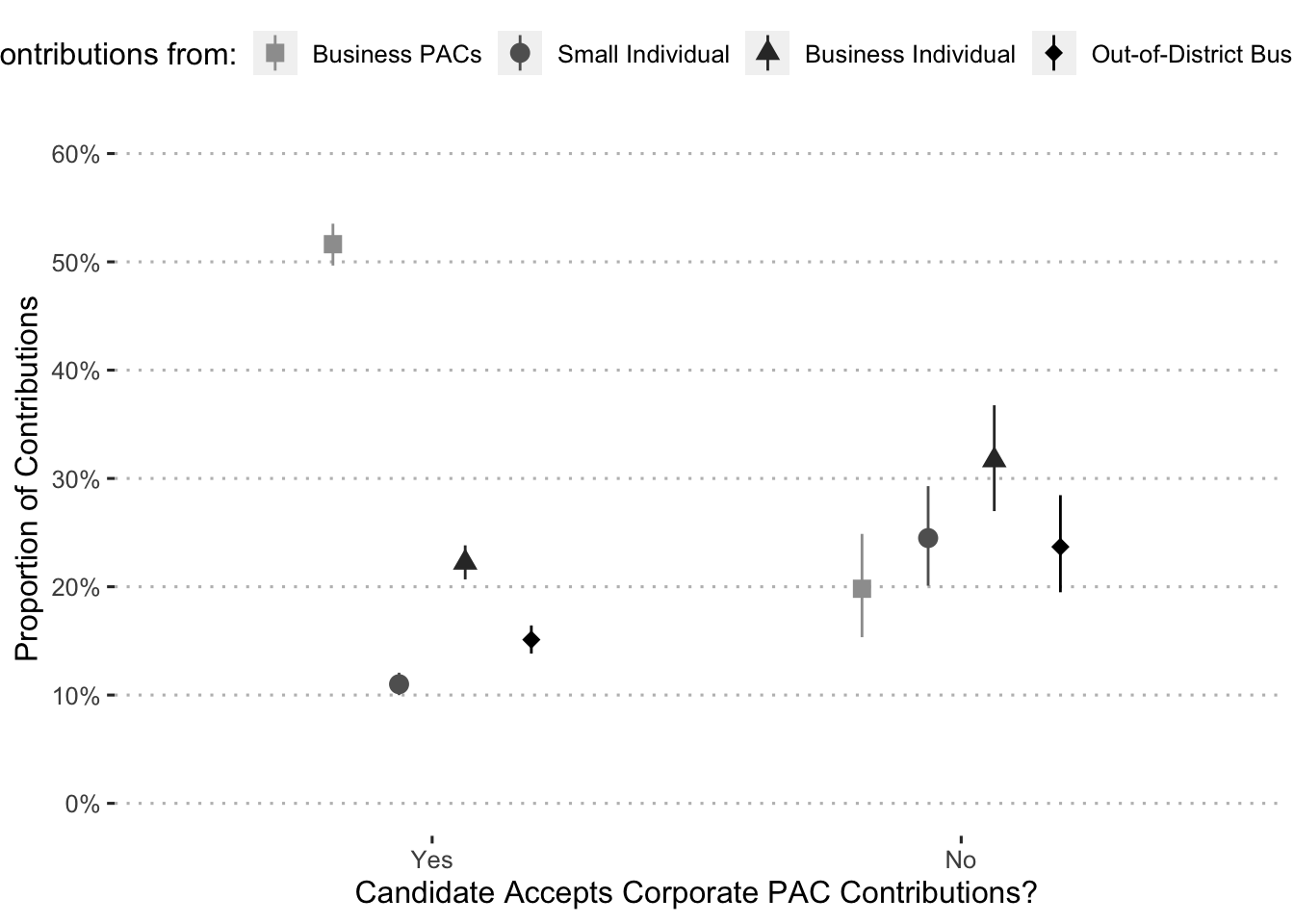
ggsave("Figures/dir_model_results.pdf", plot = last_plot(),
width = 9, height = 5)
ggplot(data = ce, aes(x = no_corp_pacs, y = estimate__, ymin = lower__,
ymax = upper__, shape = cats__, color = cats__)) +
#geom_pointinterval(position = position_dodge(width = 0.5), size = 8) +
geom_point(position = position_dodge(width = 0.5), size = 6) +
geom_linerange(position = position_dodge(width = 0.5), width = 15) +
scale_color_manual(values = c("#00AFBB", "#E7B800", "#FC4E07", "gray51"),
labels = c("Business PACs", "Small Individual",
"Business Individual",
"Out-of-District")) +
scale_shape_manual(values = c(15, 19, 17, 18),
labels = c("Business PACs", "Small Individual",
"Business Individual",
"Out-of-District")) +
labs(x = "Candidate Accepts Corporate PAC Contributions?",
y = "Proportion of Contributions",
color = "Contributions from:",
shape = "Contributions from:") +
scale_x_discrete(labels = c("Yes", "No")) +
scale_y_continuous(labels = percent_format(), limits = c(0, 0.6),
breaks = pretty_breaks(n = 6)) +
theme_pubclean()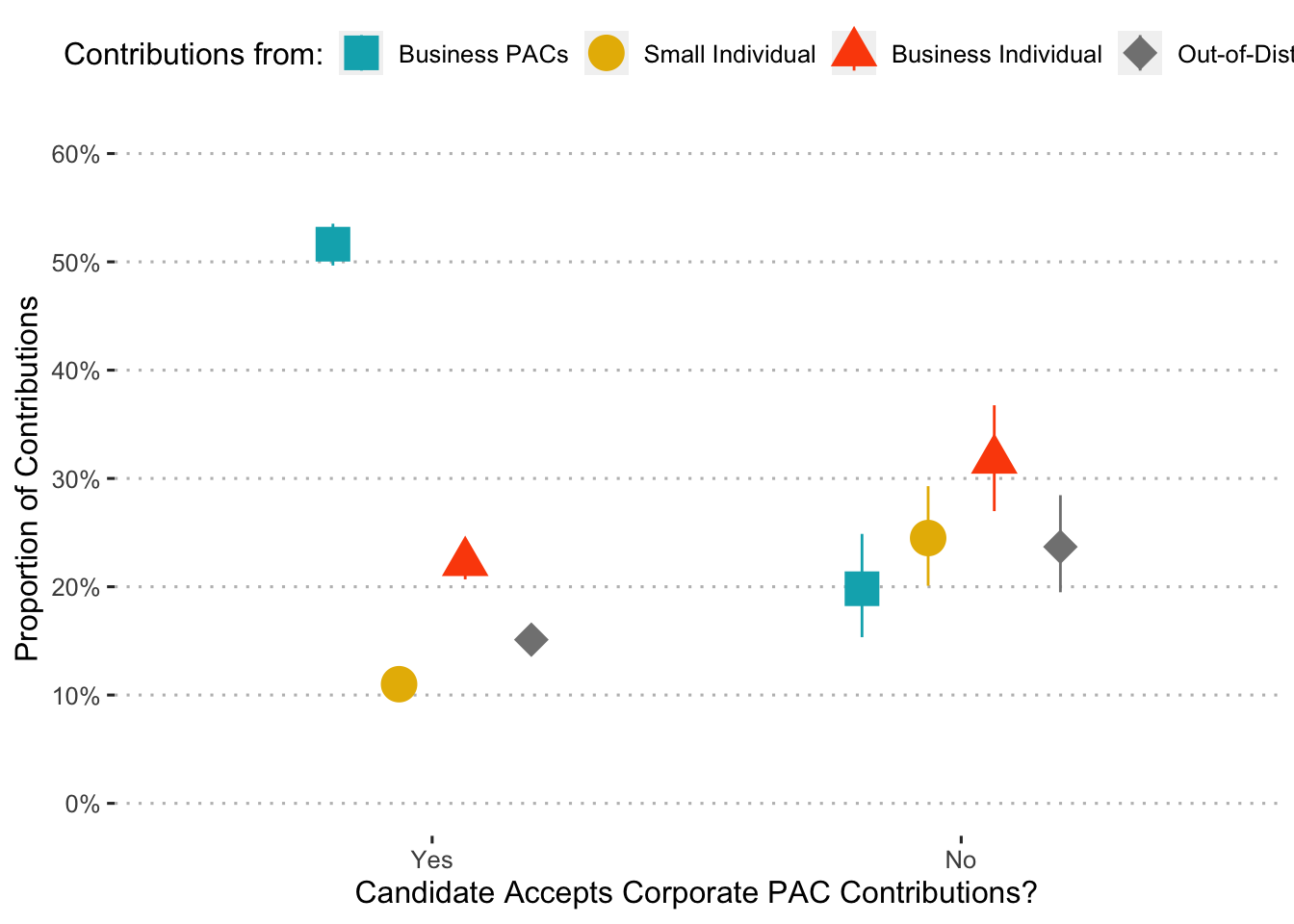
ggsave("Figures/dir_model_results_color.pdf", plot = last_plot(),
width = 8, height = 5)